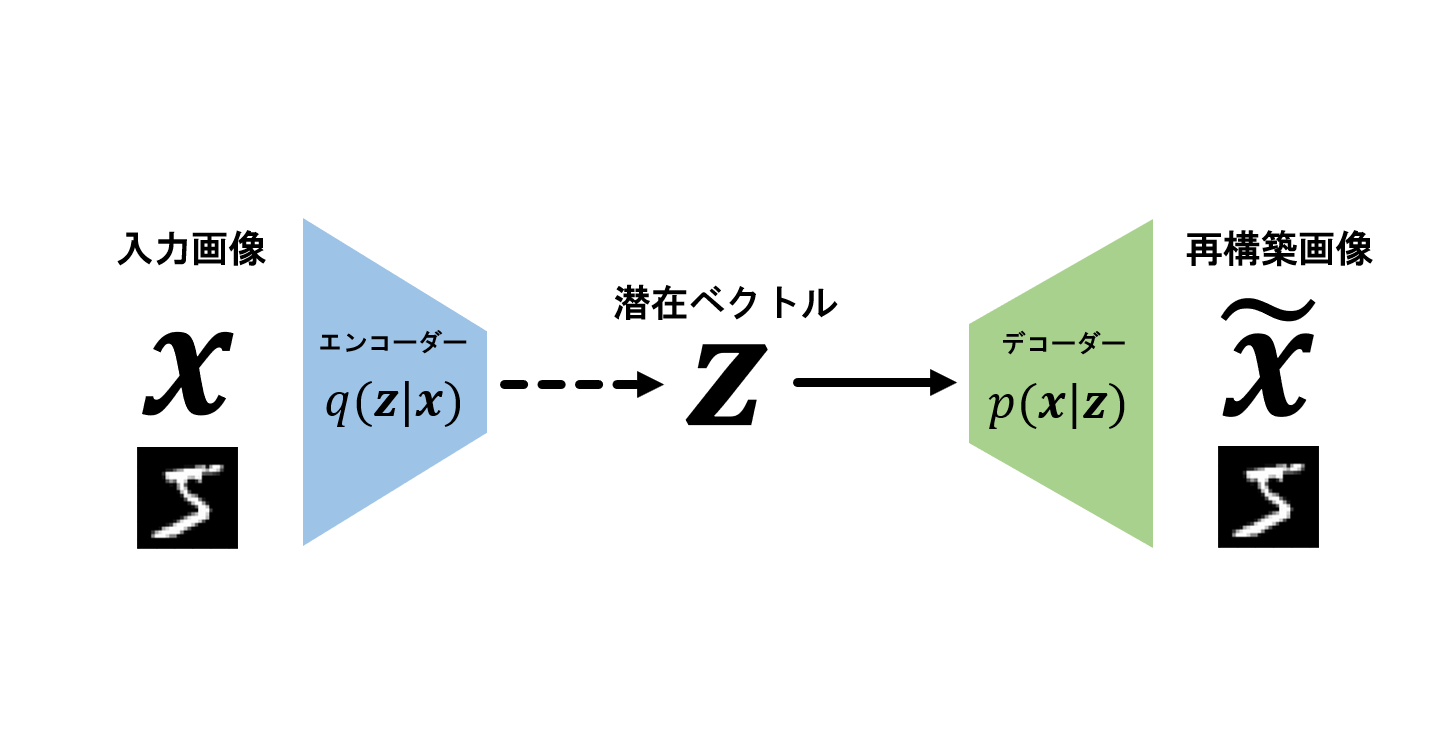
手持ちの時系列データを教師なしで異常検知する手法を探していたら、異常の種類や異常検知の発想や検知手法を網羅的に説明してくれる論文を発見したので紹介します。
時系列データの様々な種類の異常に対して、様々な発想に基づく異常検知手法が別々に研究されていますが、それらを様々な前提条件ごとにいっぺんに性能比較した論文です。
論文情報
著者:Nesryne Mejri, Laura Lopez-Fuentes, Kankana Roy, Pavel Chernakov, Enjie Ghorbel, Djamila Aouada
参考論文タイトル:Unsupervised anomaly detection in time-series: An extensive evaluation and analysis of state-of-the-art methods
掲載誌:Expert Systems with Applications, 2024, 124922.
URL:https://www.sciencedirect.com/science/article/pii/S0957417424017895
キーワードと和訳
この論文を読むうえで重要なキーワードとその和訳をリストしておきます。
- unsupervised : 教師なし
- anomaly : 異常
- detection : 検知
- time-series : 時系列
- outlier : 外れ値、異常
- paradigm : 理論の枠組み、考え方
異常の種類
異常には大きく分けて点異常とパターン異常との2種類があり、合計で5種類の異常が定義されています。
点異常
期待される値から大きく外れているような点の異常。
(a) Global Outliers
直訳すれば大域的外れ値。時系列データ全体の平均値から大きく外れているような異常。
(b) Contextual Outliers
直訳すれば文脈的外れ値。時系列データ全体ではなく、データの周辺の平均値から大きく外れているような異常。
パターン異常
一点ではなく、連続した複数点にみられる異常。
(c) Shapelet Outliers
Shapeletは直訳できないが、周期的な波形が壊れているような異常。
(d) Seasonal Outliers
直訳すれば季節性外れ値。波の形状がおかしいというよりも、周期が周りと異なるような異常。
(e) Trend Outliers
直訳すればトレンド外れ値。周期性のない部分が変動するような異常。
時系列データ異常検知の発想
クラスタリングベース
正常な時系列データ群からなる空間に入らないような時系列データを異常とみなす。
確率密度推定ベース
時系列データが異常であるとする尤度が閾値よりも高い場合に異常とみなす。
距離ベース
基準となる波形との距離、もとい、非類似度が閾値よりも高い場合に異常とみなす。
再構築ベース
モデルにより再構築された波形と実測値との距離が閾値よりも高い場合に異常とみなす。
予測ベース
モデルによる予測値と実測値との距離が閾値よりも高い場合に異常とみなす。
実験方法
各手法の元論文では別々の実験方法がとられているので、この論文では、各手法に統一的な実験方法を用いることを述べています。具体的には、データセットを複数用意すること、拡張された評価指標を複数用意すること、前処理や後処理のやり方を統一することなどです。詳細は割愛。
また、実験に用いる異常検知手法を9つ紹介しています。Shallow(?)な4手法と、ディープラーニングに基づく5手法です。ただし、距離ベースなディープラーニング手法は見つからなかったそうです。
| ベース | Shallowな手法 | Deepな手法 |
|---|---|---|
| クラスタリング | OC-SVM, iForest | THOC |
| 確率密度推定 | DA-GMM | |
| 距離 | DAMP | |
| 再構築 | USAD, (MTAD-GAT) | |
| 予測 | ARIMA | GDN, (MTAD-GAT) |
※MTAD-GATは再構築と予測のハイブリッド
実験結果
性能面
総合的にみると、MTAD-GATが一番良いF1スコアだそうです。予測ベースと再構築ベースのハイブリッドゆえに、点異常とパターン異常との両方を検知しやすいからと考えられるとのこと。
次いでGDNが二番目に良かったそうです。時系列のモデリングにはグラフ表現を利用するのが良い…らしい。
また、総合的にはディープラーニング手法のほうがF1スコアでは優位であるが、再現率(Recall)ではShallow手法のほうが優位。
そして、一変数のデータセットであっても、異常の頻度が少なすぎる場合はどの手法も苦戦するようです。
モデルサイズ
この論文ではディープラーニング手法の次元数とモデルサイズの結果も示してくれています。
その中で、GDNはパラメータ数やモデルサイズが小さい割には優秀であったことが印象的です。
反対に、USADは、データセットの次元数に比例してモデルの次元数も飛躍的に増大していくのにもかかわらず、性能的にはそれほどでもないという点も印象的です。
異常の各種に対する感度
5種類の異常の中で、トレンドの異常を検知するのが最も難しいそうです。
とはいえ、どの種類に対しても、やはりShallowな手法のほうが感度は高そうです。
一方で、ディープラーニング手法の感度はそれほど高くなく、特に、MTAD-GATはShapelet OutlierやTrend Outlierを全く検知しないそうです。
考察
著者らによる考察がいくつか示されていますが、最も印象的なのは、「時系列の異常検知においては、ディープラーニング手法が絶対的ではなく、反対に、伝統的な手法が時代遅れというわけでもない」という点であり、目的によって使い分けるべきと述べられています。(著者らが最も強調したい点は、おそらくそこではないのでしょうが…)
まとめ
時系列データの異常検知についての見識が広がったおかげで、当初の筆者の目的であった、異常検知手法をいくつか探すということがひとまず達成されました。また、それら手法の違いが実験によって明らかになったことも、この論文を見つけてよかったと思えることです。
今回は多くの箇所を割愛して紹介しましたので、興味がある方は論文のほうを読んでみてください。
筆者は早速手持ちのデータの分析に活用してみたいです。