傾向スコアマッチングを実装してみます。傾向スコアマッチングはバイアスを軽減したATE (平均処置効果) を算出する上で有効ですが、状況に応じて「傾向スコアをどのように求めるか」、「傾向スコアを用いてどうmatching/weightingするか」、「バランスチェックはどうするか」、「介入効果の分析モデルをどのように構成するか」といった手法の選択を行う必要があります。Hill, Weiss, Zhai (2011)は「留年が学生の成績に与える影響の推測」を例に、複数の手法を比較して共変量の次元が大きい際にBART (Bayesian Additive Regression Trees) が最適であることを示しています。
それでは実装していきましょう。まずは人工的にデータを発生させます。
np.random.seed(1234)
# 適当に乱数生成
x1 = np.random.rand(1000)
x2 = np.random.rand(1000)
x3 = np.random.rand(1000)
x4 = np.random.rand(1000)
x5 = np.random.gamma(5,1,1000)
x6 = np.random.rand(1000)
X = np.array([x1,x2,x3,x4,x5,x6]).T
# 適当な規則で0,1をとる乱数を生成
interve = np.zeros(1000)
interve_random_index1 = np.where((x1 > 0.5) & (x2 > 0.5))
interve_random_index2 = np.where((x3 > 0.2) & (x4 > 0.1) & (x5 > 3.0))
interve_random_index3 = np.where(x6 > 0.6)
interve[interve_random_index1] = np.random.randint(0,2,len(interve_random_index1[0]))
interve[interve_random_index2] = np.random.randint(0,2,len(interve_random_index2[0]))
interve[interve_random_index3] = np.random.randint(0,2,len(interve_random_index3[0]))
# 適当に目標変数の生成
y = 200 * x1 + 200 * x2 + 30 * x5 + 40 * interve + np.random.normal(10, 10, 1000)
X_interve = X[interve == 1]
y_interve = y[interve == 1]
X_non_interve = X[interve == 0]
y_non_interve = y[interve == 0]
print(f'biased ATE = {np.sum(y_interve)/len(y_interve) - np.sum(y_non_interve)/len(y_non_interve):.2f}')
fig = plt.figure(figsize = (15,10))
for i in range(6):
ax = fig.add_subplot(2,3,i+1)
ax.scatter(X_interve[:,i], y_interve, s = 10, label = 'interve',
color = 'red', alpha = 0.5)
ax.scatter(X_non_interve[:,i], y_non_interve, s = 10, label = 'non interve',
color = 'blue', alpha = 0.5)
ax.set_xlabel(f'x{i+1}')
ax.set_ylabel('y')
ax.legend()
plt.show()
fig.savefig('Scatter.png')###出力###
biased ATE = 69.13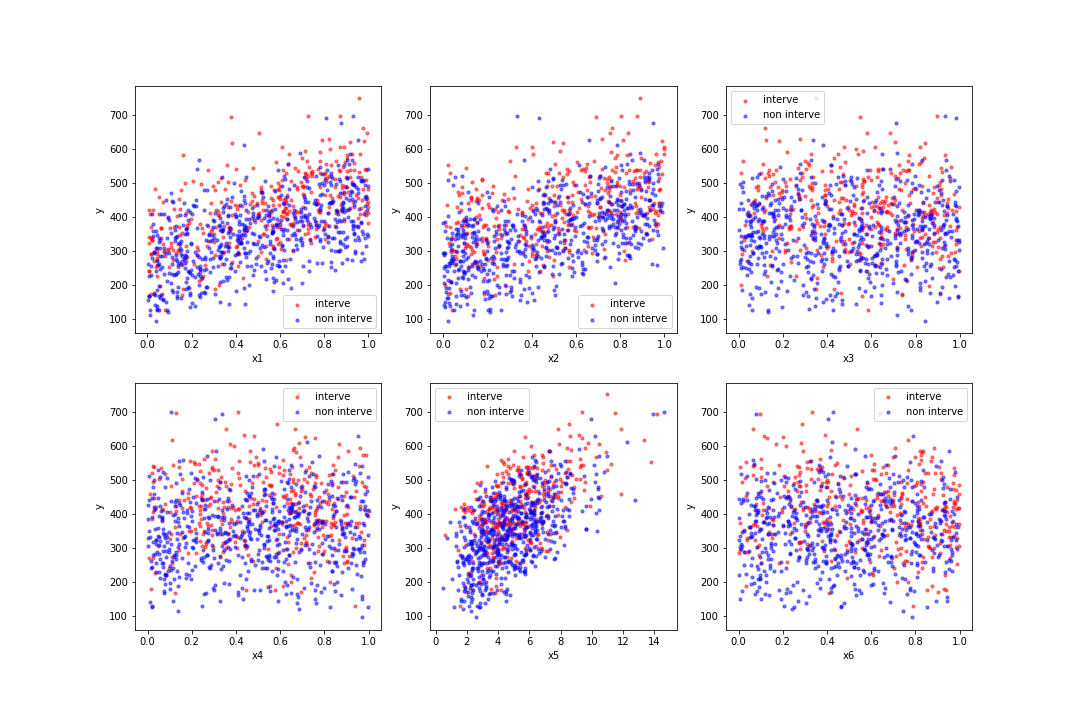
介入と非介入が大体半々くらいになるようにデータを発生させ、+40の介入効果がある、という目的変数を作りました。また目的変数には介入変数以外にもいくつかの共変量に影響されています。単純に標本平均でATEを算出すると+69.13とかなり介入効果を過大評価してしまいます。
ここからは、傾向スコアマッチングによって真の介入効果を探っていきます。なお、「傾向スコア」、「傾向スコアマッチング」についての基本的な説明は省略しますのでこちらの記事を参考にしてください。
1.傾向スコア算出
1.1ロジスティック回帰
傾向スコアマッチングで最もスタンダードな手法です。sklearnで簡単に実装できます。
#---
# ロジスティック回帰による傾向スコアの算出
#---
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_std = sc.fit_transform(X)
interve = interve.astype(np.uint8)
model = LogisticRegression(max_iter = 100, multi_class = 'ovr', solver = 'liblinear',
C = 1.0, penalty = 'l2', l1_ratio = None, random_state = 0)
model.fit(X_std, interve)
X_std = X_std.T # (6, 1000)
coef = model.coef_.reshape(6)
intercept = model.intercept_
PS_LR= 1 / (1 + np.exp(-intercept - coef @ X_std))
LR_pred = model.predict(X_std.T)
LR_accuracy = np.sum(LR_pred == interve) / len(interve)
print(f'LR accuracy: {LR_accuracy * 100 :.2f}%')
fig = plt.figure(figsize = (8,8))
bins = np.linspace(0, 1, 50)
plt.hist(PS_LR[interve == 1], bins = bins, color = 'red', alpha = 0.5, label = 'interve', density = True)
plt.hist(PS_LR[interve == 0], bins = bins, color = 'blue', alpha = 0.5, label = 'non interve', density = True)
plt.legend()
plt.xlabel('PS')
plt.ylabel('density')
plt.title('Propensity score by LogisticRegression')
plt.show()
fig.savefig('Histgram_of_PS_log.png')###出力###
LR accuracy: 60.90%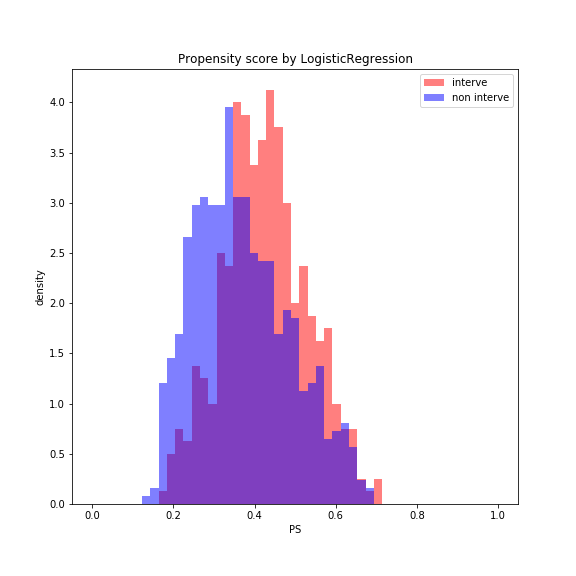
傾向スコアを算出する上で分類性能はさほど重要ではありませんが、一応求めたaccuracyは60.90%でした。interve/non interveをそこそこ分離できている様子がわかります。
一般に、簡単な問題では傾向スコア算出にはロジスティック回帰で十分ですが、Hill, Weiss, Zhai (2011)は共変量の次元が高くなるとロジスティック回帰には回帰係数が無限大になってしまう「完全分離」の問題があると指摘し、その対処法としてBARTを紹介しています。
1.2 BART
BARTはBaysian CARTと呼ばれる決定木の線形和を取る手法です。Baysian CARTはHugh Chipmanが概説しており、その日本語訳及び注釈をまとめたのでご覧ください。
理論を抑えたら次にBARTをPythonで実装していきましょう。Pythonには木構造を簡単に表現できるnetworkxというライブラリが存在します。実装は
- 事前分布を表現する関数を定義
- 提案分布を定義
- 受容確率を算出する関数を定義
- サンプリングを行う関数を定義
という手順で行っていきます。
import networkx as nx
np.random.seed(1234)
#---
# 1.事前分布を表現
#---
def split(d, alpha = 0.95, beta = 2):
p_split = alpha * (1 + d) ** (-beta)
return np.random.binomial(1, p = p_split)
def rule(X):
p = X.shape[1]
x_i = np.random.randint(p)
threshold = (max(X[:,x_i]) - min(X[:,x_i])) * np.random.rand() + min(X[:,x_i])
return x_i, threshold
class Node:
def __init__(self, d, x_i = None, threshold = None, terminal = False, mu = None, upper = True):
self.terminal = terminal
self.d = d
self.upper = upper
if self.terminal:
self.mu = mu
else:
self.x_i = x_i
self.threshold = threshold
class StackClass: # 探索用のスタックオブジェクトを用意
def __init__(self):
self.list_data = []
def push(self, item1):
return self.list_data.append(item1)
def pop(self):
val = self.list_data[len(self.list_data)-1]
del self.list_data[len(self.list_data)-1]
return val
def prior_T(X, nu = 10, lam = 1/2, a = 2): # 事前分布からグラフのサンプルを一つ取り出す関数(深さ優先探索)
d = 0
T = nx.DiGraph()
x_i, threshold = rule(X)
initial_node = Node(d = 0, x_i = x_i, threshold = threshold, terminal = False)
T.add_node(initial_node)
Stack = StackClass()
Stack.push(initial_node)
while len(Stack.list_data) > 0:
parent = Stack.pop()
if split(parent.d) == 1:
child_x1, child_threshold1 = rule(X)
child_x2, child_threshold2 = rule(X)
child_node1 = node(d = parent.d + 1,
x_i = child_x1, threshold = child_threshold1,
terminal = False, upper = True)
child_node2 = node(d = parent.d + 1,
x_i = child_x2, threshold = child_threshold2,
terminal = False, upper = False)
T.add_node(child_node1)
T.add_node(child_node2)
T.add_edge(parent, child_node1)
T.add_edge(parent, child_node2)
Stack.push(child_node1)
Stack.push(child_node2)
else:
parent.terminal = True
sigma = 1 / np.random.gamma(nu/2,nu*lam/2)
parent.mu = np.random.normal(0.5 / 200, sigma / a)
return T- split:末端ノードの深さが与えられた時、そのノードを分割するか否かを0or1で返す関数
- rule:どの共変量によって分割するか、閾値はどうするかをランダムに決める関数
- node:ノードを表現するクラス。ノードの深さd、前のノードで閾値より大きいデータが来るのか否かを示すupper、末端ノードであるか否かを示すterminal、推定値を示すmuなどの情報を持つ。
- prior_T:深さ優先探索の要領で木を一本ランダムに取り出す関数。StackClassは深さ優先探索のために使うクラス。
#---
# 2.提案分布からのサンプリング
#---
def GROW(T, nu = 10, lam = 1/2, a = 2):
while True:
terminal_node = list(T.nodes)[np.random.randint(0,len(T.nodes))]
if terminal_node.terminal:
break
terminal_node.terminal = False
terminal_xi, terminal_threshold = rule(X)
terminal_node.x_i = terminal_xi
terminal_node.threshold = terminal_threshold
sigma = 1 / np.random.gamma(nu/2,nu*lam/2)
child_node1 = node(d = terminal_node.d + 1,
terminal = True, mu = np.random.normal(0.5 / 200, sigma / a), upper = True)
child_node2 = node(d = terminal_node.d + 1,
terminal = True, mu = np.random.normal(0.5 / 200, sigma / a), upper = False)
T.add_node(child_node1)
T.add_node(child_node2)
T.add_edge(terminal_node, child_node1)
T.add_edge(terminal_node, child_node2)
return T
def PRUNE(T, nu = 10, lam = 1/2, a = 2):
while True:
if len(list(T.nodes)) == 1:
break
parent_node = list(T.nodes)[np.random.randint(0,len(T.nodes))]
if list(T.successors(parent_node)) != []:
child_node1 = list(T.successors(parent_node))[0]
child_node2 = list(T.successors(parent_node))[1]
if child_node1.terminal and child_node2.terminal:
T.remove_node(child_node1)
T.remove_node(child_node2)
parent_node.terminal = True
sigma = 1 / np.random.gamma(nu/2,nu*lam/2)
parent_node.mu = np.random.normal(0.5 / 200, sigma / a)
break
return T
def CHANGE(T):
if len(list(T.nodes)) == 1:
return T
while True:
internal_node = list(T.nodes)[np.random.randint(0,len(T.nodes))]
if internal_node.terminal == False:
x_i, threshold = rule(X)
internal_node.x_i = x_i
internal_node.threshold = threshold
break
return T
def SWAP(T):
if len(list(T.nodes)) <= 7:
return T
count = 0
for i in range(30):
parent_node = list(T.nodes)[np.random.randint(0,len(T.nodes))]
if parent_node.terminal == False:
if list(T.successors(parent_node))[0].terminal == False:
child_node = list(T.successors(parent_node))[0]
break
elif list(T.successors(parent_node))[1].terminal == False:
child_node = list(T.successors(parent_node))[1]
break
if i == 29:
return T
x1, threshold1 = parent_node.x_i, parent_node.threshold
x2, threshold2 = child_node.x_i, child_node.threshold
parent_node.x_i = x2
parent_node.threshold = threshold2
child_node.x_i = x1
child_node.threshold = threshold1
return T- GROW、PRUNE、CHANGE、SWAP:提案分布からのサンプリングを行うための関数。それぞれの役割については先述の通り。
#---
# 受容確率の算出
#---
def g(T, x):
initial_node = list(T.nodes)[0]
Stack = StackClass()
Stack.push(initial_node)
while len(Stack.list_data) > 0:
parent_node = Stack.pop()
if parent_node.terminal:
return parent_node.mu, parent_node
else:
child_node1 = list(T.successors(parent_node))[0]
child_node2 = list(T.successors(parent_node))[1]
if parent_node.threshold < x[parent_node.x_i]:
if child_node1.upper:
Stack.push(child_node1)
else:
Stack.push(child_node2)
else:
if child_node1.upper:
Stack.push(child_node2)
else:
Stack.push(child_node1)
def log_LIKE(Ts, j, X, y, nu = 10, lam = 1/2, a = 2, test = False):
if test:
prediction = []
y_ = np.array(y).astype(float)
terminal_nodes = []
n_i = np.array([]).astype(float)
y_i = np.array([]).astype(float)
y_i2 = np.array([]).astype(float)
mu_bar = 0.5 / 200
for i in range(len(X)):
pred, terminal_node = g(Ts[j], X[i])
if test:
prediction.append(pred)
continue
R = 0
for k in range(len(Ts)):
if k != j:
R += g(Ts[k], X[i])[0]
y_[i] -= R
if terminal_node not in terminal_nodes:
terminal_nodes.append(terminal_node)
y_i = np.append(y_i, y_[i])
y_i2 = np.append(y_i2, y_[i]**2)
n_i = np.append(n_i,1)
else:
y_i[terminal_nodes.index(terminal_node)] += y_[i]
y_i2[terminal_nodes.index(terminal_node)] += y_[i] ** 2
n_i[terminal_nodes.index(terminal_node)] += 1
b = len(n_i)
n = np.sum(n_i)
sigma = 1 / np.random.gamma(nu/2,nu*lam/2)
y_bar = y_i / n_i
s_i = y_i2 - n_i * (y_bar ** 2)
t_i = (n_i * a) / (n_i + a) * (y_bar - mu_bar) ** 2
loglikelihood = b/2 * np.log(a) - 1/2 * np.sum(np.log(n_i + a)) - (n + nu)/2 * np.log(np.sum(s_i+t_i) + nu*lam)
mus = np.random.normal((n_i * y_bar + a * mu_bar) / (n_i + a), sigma / (n_i + a))
if test:
return prediction
else:
return loglikelihood, terminal_nodes, mus
def alpha(Ts, Ts_, j, X, y):
log_, terminal_nodes, mus = log_LIKE(Ts_, j, X, y)
log = log_LIKE(Ts, j, X, y)[0]
return min(np.exp(log_ - log), 1), terminal_nodes, mus- g:木Tとデータxが与えられた時に、Tによる推定量を求める関数。
- log_LIKE:木のリストTsと該当する木のインデックスj、データX,yが与えられた時の木の事後対数尤度を計算する関数。この計算方法については先述の通り。
- alpha:受容確率を計算する関数。提案分布が対象であるため酔歩連鎖MHアルゴリズムと同様に、log_LIKEの比で求めることができる。
#---
# ギブスサンプリング、MHアルゴリズム
#---
def GS(X, y, tree_num = 200, warmup = 50, sampling = 10):
mean_treenum_list = []
loglike_list = []
Ts_list = [[prior_T(X) for _ in range(tree_num)]]
func_list = [GROW, PRUNE, CHANGE, SWAP]
for i in range(warmup):
for j in range(tree_num):
if j == 0:
mean_treenum_list.append( (len(list(Ts_list[0][j].nodes))//2+1) / tree_num )
loglike_list.append( log_LIKE(Ts_list[0], j, X, y)[0] / tree_num )
else:
mean_treenum_list[-1] += (len(list(Ts_list[0][j].nodes))//2+1) / tree_num
loglike_list[-1] += log_LIKE(Ts_list[0], j, X, y)[0] / tree_num
func = np.random.randint(0,4)
Ts_ = copy.deepcopy(Ts_list[0])
T_ = copy.deepcopy(Ts_list[0][j])
T_ = func_list[func](T_)
Ts_[j] = T_
alp, terminal_nodes, mus = alpha(Ts_list[0], Ts_, j, X, y)
if np.random.binomial(1, alp) == 1:
for k in range(len(terminal_nodes)):
terminal_nodes[k].mu = mus[k]
Ts_list.append(Ts_)
del Ts_list[0]
else:
Ts_list.append(Ts_list[0])
del Ts_list[0]
print(f'warmup| epoch:{i+1}, loglikelihood:{loglike_list[-1]:.2f}')
print('warmup ended')
for i in range(sampling):
for j in range(tree_num):
func = np.random.randint(0,4)
Ts_ = copy.deepcopy(Ts_list[i])
T_ = copy.deepcopy(Ts_list[i][j])
T_ = func_list[func](T)
Ts_[j] = T_
alp, terminal_nodes, mus = alpha(Ts_list[i], Ts_, j, X, y)
if np.random.binomial(1, alp) == 1:
for k in range(len(terminal_nodes)):
terminal_nodes[k].mu = mus[k]
Ts_list.append(Ts_)
else:
Ts_list.append(Ts_list[i])
print('sampling ended')
return Ts_list, loglike_list, mean_treenum_list- GS:ギブスサンプリングを行う関数。
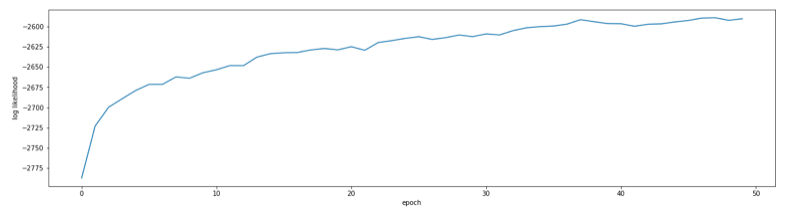
Ts_list, loglike_list, mean_treenum_list = GS(X, interve)###出力###
warmup| epoch:1, loglikelihood:-2787.48
warmup| epoch:2, loglikelihood:-2723.22
warmup| epoch:3, loglikelihood:-2699.82
warmup| epoch:4, loglikelihood:-2689.43
warmup| epoch:5, loglikelihood:-2679.17
...
warmup| epoch:50, loglikelihood:-2590.24
warmup ended
sampling ended50epochまでは稼働検査期間としてサンプリングせずに捨てています。loglike_listとmean_treenum_listを描画すると次のようになります。
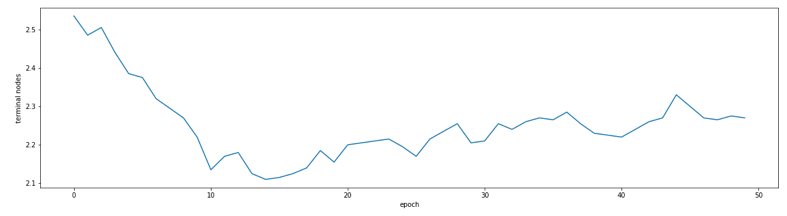
BARTによって傾向スコアを算出します。
PS_BART = np.zeros(len(interve))
for Ts in Ts_list:
PS = np.zeros(len(interve))
for j in range(200):
PS += np.array(log_LIKE(Ts, j, X, interve, test = True))
PS_BART += PS / 2000
BART_pred = PS_BART.copy()
BART_pred[BART_pred > 0.5] = 1
BART_pred[BART_pred <= 0.5] = 0
BART_accuracy = np.sum(BART_pred == interve) / len(interve)
print(f'BART accuracy: {BART_accuracy * 100 :.2f}%')
fig = plt.figure(figsize = (8,8))
bins = np.linspace(0, 1, 50)
plt.hist(PS_BART[interve == 1], bins = bins, color = 'red', alpha = 0.5, label = 'interve', density = True)
plt.hist(PS_BART[interve == 0], bins = bins, color = 'blue', alpha = 0.5, label = 'non interve', density = True)
plt.legend()
plt.xlabel('PS')
plt.ylabel('density')
plt.title('Propensity score by BART')
plt.show()
fig.savefig('Histgram_of_PS_BART.png')###出力###
BART accuracy: 77.40%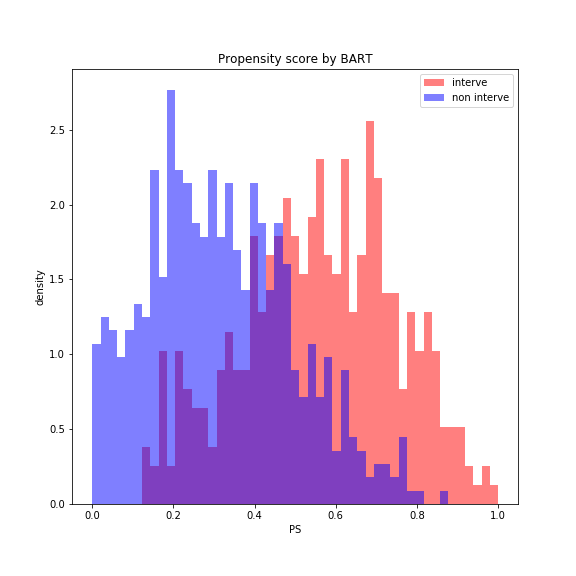
accuracyはロジスティック回帰を行うよりもはるかに高くなりました。介入と非介入をかなり分離しています。
2.マッチング
傾向スコアをもとにマッチングを行います。
def Matching(PS_interve, PS_non_interve):
interve_index = []
non_interve_index = []
PS_interve = PS_interve.reshape(len(PS_interve), 1)
distance_matrix = np.sqrt( (PS_interve - PS_non_interve) ** 2)
while np.min(distance_matrix) < 0.01:
i, j = np.unravel_index(np.argmin(distance_matrix), distance_matrix.shape)
interve_index.append(i)
non_interve_index.append(j)
distance_matrix[i,:] = 1
distance_matrix[:,j] = 1
return interve_index, non_interve_index
PS_LR_interve = PS_LR[interve == 1]
PS_LR_non_interve = PS_LR[interve == 0]
LR_matched_interve_index, LR_matched_non_interve_index = Matching(PS_LR_interve, PS_LR_non_interve)
LR_matched_X_interve = X_interve[LR_matched_interve_index]
LR_matched_X_non_interve = X_non_interve[LR_matched_non_interve_index]
LR_matched_y_interve = y_interve[LR_matched_interve_index]
LR_matched_y_non_interve = y_non_interve[LR_matched_non_interve_index]
print(f'ATE by LR matching = {np.sum(LR_matched_y_interve)/len(LR_matched_y_interve) - np.sum(LR_matched_y_non_interve)/len(LR_matched_y_non_interve):.2f}')
PS_BART_interve = PS_BART[interve == 1]
PS_BART_non_interve = PS_BART[interve == 0]
BART_matched_interve_index, BART_matched_non_interve_index = Matching(PS_BART_interve, PS_BART_non_interve)
BART_matched_X_interve = X_interve[BART_matched_interve_index]
BART_matched_X_non_interve = X_non_interve[BART_matched_non_interve_index]
BART_matched_y_interve = y_interve[BART_matched_interve_index]
BART_matched_y_non_interve = y_non_interve[BART_matched_non_interve_index]
print(f'ATE by BART matching = {np.sum(BART_matched_y_interve)/len(BART_matched_y_interve) - np.sum(BART_matched_y_non_interve)/len(BART_matched_y_non_interve):.2f}')###出力###
ATE by LR matching = 38.62
ATE by BART matching = 29.37本来の介入効果は+40で、共変量のバイアス付きのATEは+69.13と介入効果を過大に推定してしまっていました。ロジスティック回帰とBARTによって推定したATEは共変量のバイアスを軽減できていますが、ロジスティック回帰の方が真の介入効果の値に近くなっています。しかし、本来のデータでは真の介入効果との近似精度は観測することはできません。そこで次は、複数の手法が与えられた時、データに対してどれを使うのが適切かを調べるバランスチェックの手法を見ていきます。
3.バランスチェック
バランスチェックには「共変量プロット」、「QQプロット」がよく使われます。Pythonには専用のライブラリはないので一から実装します。
def plot_balance(X_interve, X_non_interve, matched_X_interve, matched_X_non_interve, X_list):
mean_interve = np.mean(X_interve, axis = 0)
mean_non_interve = np.mean(X_non_interve, axis = 0)
var_interve = np.mean(X_interve ** 2, axis = 0) - mean_interve ** 2
var_non_interve = np.mean(X_non_interve ** 2, axis = 0) - mean_non_interve ** 2
Unadjusted_Balance = abs(mean_interve - mean_non_interve) / np.sqrt((var_interve + var_non_interve) / 2)
mean_matched_interve = np.mean(matched_X_interve, axis = 0)
mean_matched_non_interve = np.mean(matched_X_non_interve, axis = 0)
var_matched_interve = np.mean(matched_X_interve ** 2, axis = 0) - mean_matched_interve ** 2
var_matched_non_interve = np.mean(matched_X_non_interve ** 2, axis = 0) - mean_matched_non_interve ** 2
Adjusted_Balance = abs(mean_matched_interve - mean_matched_non_interve) / np.sqrt((var_matched_interve + var_matched_non_interve) / 2)
plt.plot(X_list, Unadjusted_Balance, marker = 'o', linestyle = '-', label = 'Unadjusted')
plt.plot(X_list, Adjusted_Balance, marker = 'o', linestyle = '-', label = 'Adjusted')
plt.legend()
plt.ylabel('Covariate Balance')
plt.show()
import math
def QQ_plot(X_interve, X_non_interve):
sorted_X_interve = np.sort(X_interve, axis = 0)
sorted_X_non_interve = np.sort(X_non_interve, axis = 0)
gcd = math.gcd(len(sorted_X_interve), len(sorted_X_non_interve))
fig = plt.figure(figsize = (15,10))
for i in range(len(X_list)):
interve_x_i = sorted_X_interve[:,i]
non_interve_x_i = sorted_X_non_interve[:,i]
interve_quantile = np.array(np.array_split(interve_x_i, gcd))[:,0]
non_interve_quantile = np.array(np.array_split(non_interve_x_i, gcd))[:,0]
ax = fig.add_subplot(2,3,i+1)
x = [non_interve_quantile[0], non_interve_quantile[-1]]
y = [interve_quantile[0], interve_quantile[-1]]
ax.plot(x, y, marker = None, linestyle = 'dashed', linewidth = 0.5, color = 'k')
ax.plot(non_interve_quantile, interve_quantile)
ax.set_xlabel(f'non interve (x{i+1})')
ax.set_ylabel(f'interve')
plt.show()plot_balance関数で共変量プロットを描きます。
plot_balance(X_interve, X_non_interve, LR_matched_X_interve, LR_matched_X_non_interve, X_list)
plot_balance(X_interve, X_non_interve, BCART_matched_X_interve, BCART_matched_X_non_interve, X_list)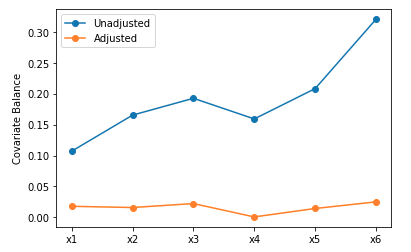
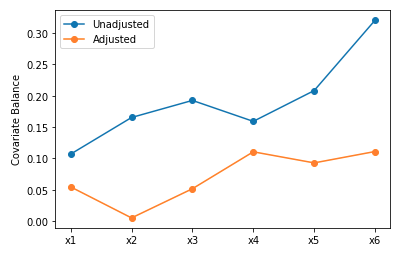
ロジスティック回帰(上)の方がバランスよくマッチングできていることがわかります。
QQ_plot関数でQQプロットを描きます。
QQ_plot(X_interve, X_non_interve)
QQ_plot(LR_matched_X_interve, LR_matched_X_non_interve)
QQ_plot(BCART_matched_X_interve, BCART_matched_X_non_interve)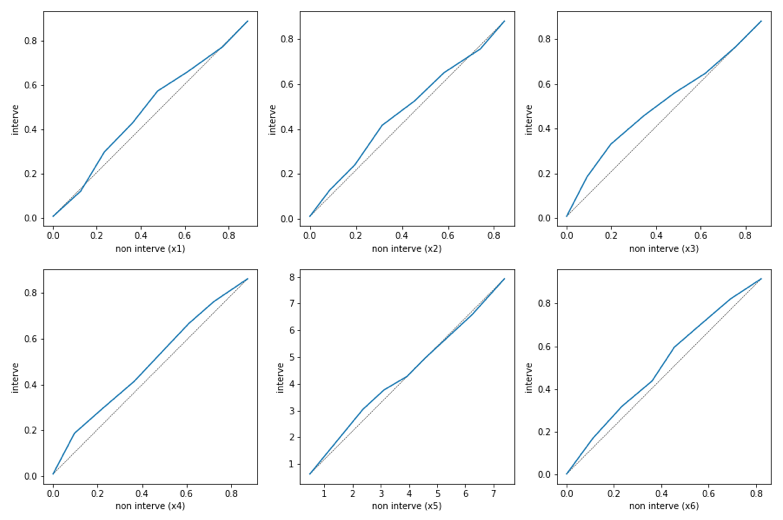
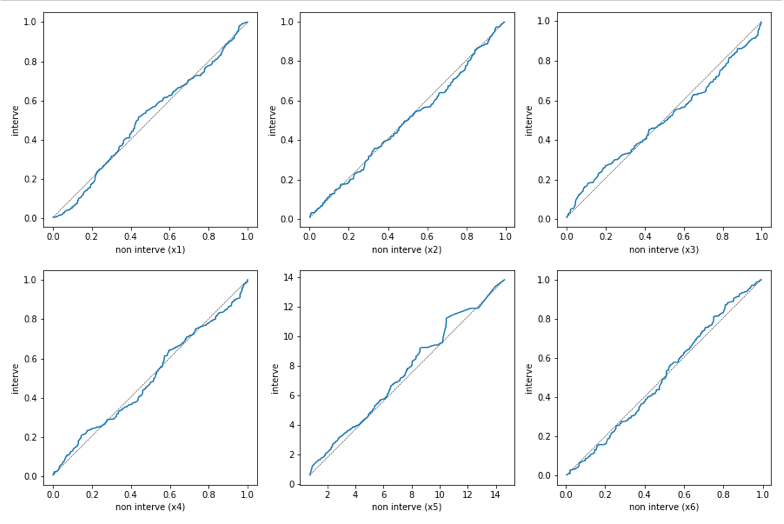
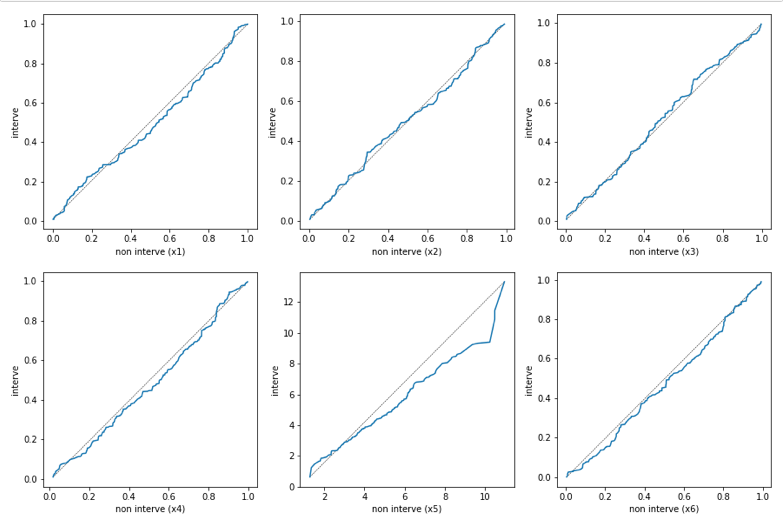
バイアスが残ったままのデータ(上)では共変量の分布に偏りが見られますが、ロジスティック回帰、BARTによるマッチングをおこなったデータ(中、下)は分布の偏りが改善しています。また、QQプロットでみてもロジスティック回帰の方が理想的にマッチングしているようです。
4.おわりに
ロジスティック回帰とBARTを使って、共変量のバイアスがあるデータから真の介入効果を推定しました。今回は介入変数が6つ(実際に介入させたのは3つ)のシンプルなデータを用いたためロジスティック回帰の方がより精度良く分類できました。しかし、Hill, Weiss, Zhai (2011)は250種類以上の共変量を用いていたように、ロジスティック回帰ではうまくいかない状況でBARTが役に立つ場合があります。
現実のデータでは説明変数が膨大でどれを共変量として選ぶかが難しい、という問題は頻発します。また単純に分類性能で見てもロジスティック回帰よりもBARTの方が優秀だったため、機械学習手法としてもBARTがもっと活用されても良いのではないでしょうか。
今回は以上になります。また効果検証に関する話題を記事にしたいと思います。最後までお読みいただきありがとうございました。