
はじめに
機械学習勉強し始めて早3ヶ月の新入社員です。日々精進をしています。
今回はその勉強のアウトプットも兼ねて、下記サイト
https://rikapoke.hatenablog.jp/entry/pokemon_datasheet_gne7
で公開されているポケットモンスターシリーズに出てきたポケモンの特徴をまとめたcsvデータを元に、分析およびモデル構築を行い、一部コードとその結果と考察を纏めました。
長くなったために以下の様に記事を前編・後編に分けました。
内容は大まかに以下の通りです
- 【前編】ポケモンのタイプを固有の能力値パラメータを元に予測するモデルを構築する【単純集計】
- データ内容の確認
- モデル構築用にデータの加工
- データの集計と図示化
- 【後編】ポケモンのタイプを固有の能力値パラメータを元に予測するモデルを構築する 【LightGBM】
- LightGBMでモデルを構築する
- ハイパーパラメータチューニング
- テストデータを使用してモデルの評価する
データ内容の確認
まず、大元のcsvファイルをインポートしてデータの詳細を確認します。
この際、info メソッドを使用すると サンプル数・カラム名・NaNデータの数・各カラムのデータタイプなどの様々な情報が一気に手に入って便利です。
#データの加工
import numpy as np
import pandas as pd
#図示化
import matplotlib.pyplot as plt
from matplotlib import cm
import japanize_matplotlib
import seaborn as sns
# データをインポート、変数 pokemon に格納
pokemon = pd.read_csv("pokemon_status.csv", delimiter=',', header=0,encoding="SHIFT-JIS")
# データの詳細
pokemon.info()
infoメソッドによって、pokemonデータ構造は以下の様になっていることがわかります。
| Column | Non-Null Count | Data type | 説明 |
|---|---|---|---|
| 図鑑番号 | 909 non-null | object | |
| ポケモン名 | 909 non-null | object | |
| タイプ1 | 909 non-null | object | ポケモン固有の属性。2つ持つポケモンもいる。 |
| タイプ2 | 487 non-null | object | 〃 |
| 通常特性1 | 909 non-null | object | ポケモン毎の特殊スキル。個体毎に持ってる特性が違う |
| 通常特性2 | 458 non-null | object | 〃 |
| 夢特性 | 729 non-null | object | 〃 |
| HP | 909 non-null | int64 | ポケモンの種族毎に決められている「体力」のパラメータ |
| こうげき | 909 non-null | int64 | 〃 「攻撃力」のパラメータ |
| ぼうぎょ | 909 non-null | int64 | 〃 「防御力」のパラメータ |
| とくこう | 909 non-null | int64 | 〃 「特殊攻撃力」のパラメータ |
| とくぼう | 909 non-null | int64 | 〃 「特殊防御力」のパラメータ |
| すばやさ | 909 non-null | int64 | 〃 「素早さ」のパラメータ |
| 合計 | 907 non-null | float64 | 上記能力値パラメータの合計値 |
909種類のポケモン、その固有のスキル (カテゴリ) と固有の能力値パラメータ (数値) が格納されていることがわかります。
能力値パラメータの合計値が907個で数が合わないのが気になります。確認してみましょう。
# 合計がNaNになっているデータを出力する。
print(pokemon[pokemon["合計"].isna()]) #814, 815
| index | 図鑑番号 | ポケモン名 | タイプ1 | タイプ2 | 通常特性1 | 通常特性2 | 夢特性 | HP | こうげき | ぼうぎょ | とくこう | とくぼう | すばやさ | 合計 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 814 | 718 | ジガルデ10% | ドラゴン | じめん | オーラブレイク | スワームチェンジ | 54 | 100 | 71 | 61 | 85 | 115 | 486 | NaN |
| 815 | 718-1 | ジガルデ50% | ドラゴン | じめん | オーラブレイク | スワームチェンジ | 108 | 100 | 121 | 81 | 95 | 95 | 600 | NaN |
どうやら、夢特性にセルが一個ずつずれた結果合計がNaNになってしまったデータな様です。作業が面倒くさいので 今回の分析ではジガルデ10%,50%のデータは取り除くことにします。
#index = 814, 815 (ジガルデ10%, 50%) は取り除く
error = pokemon.iloc[[814,815],:]
pokemon = pokemon.drop(error.index).reset_index(drop=True)
モデル構築用にデータの加工
モデリングに使用するためにデータを加工します。
タイトルにある様に、ポケモンの固有の能力値 (HP, こうげき,ぼうぎょ,とくこう,とくぼう,すばやさ,合計) を元にそのポケモンのタイプを予測するモデルを構築したいため以下の処理をそれぞれのデータに対して行います。
- ポケモンのタイプと固有の能力値以外のカラムを除去する
- タイプが2つあるポケモンの場合、両方のタイプとしてカウントする
これによって得られたデータをdf_typeとして格納します。
df = pokemon.loc[:, ['タイプ1', 'タイプ2', 'HP', 'こうげき', 'ぼうぎょ',
'とくこう', 'とくぼう', 'すばやさ','合計']]
## 2タイプある場合、両方のタイプとしてカウントする。
df_type1 = df.loc[:, ['タイプ1', 'HP', 'こうげき', 'ぼうぎょ',
'とくこう', 'とくぼう', 'すばやさ','合計']].rename(columns={'タイプ1':"タイプ"})
df_type2 = df.loc[:, ['タイプ2', 'HP', 'こうげき', 'ぼうぎょ',
'とくこう', 'とくぼう', 'すばやさ','合計']].rename(columns={'タイプ2':"タイプ"}).dropna()
df_type = pd.concat([df_type1,df_type2]).reset_index(drop=True)
データの集計と図示化
データの加工が終わったので、まず簡単にデータを集計して図示化しようと思います。
まずデータ内のタイプ別ポケモン数をプロットします。matplotlibのライブラリで簡単にできます。
#タイプ毎にデータ個数を集計
df_pokemon_num = df_type.groupby("タイプ").count().loc[:,"合計"]
#x軸をそれぞれのタイプ・y軸をポケモン数としてプロット
plt.figure(figsize=(20,5))
x = list(range(len(df_pokemon_num)))
plt.bar(x, df_pokemon_num.values)
plt.xticks(x,df_pokemon_num.index)
plt.xlabel("タイプ")
plt.ylabel("ポケモン数")
plt.grid()
plt.show()
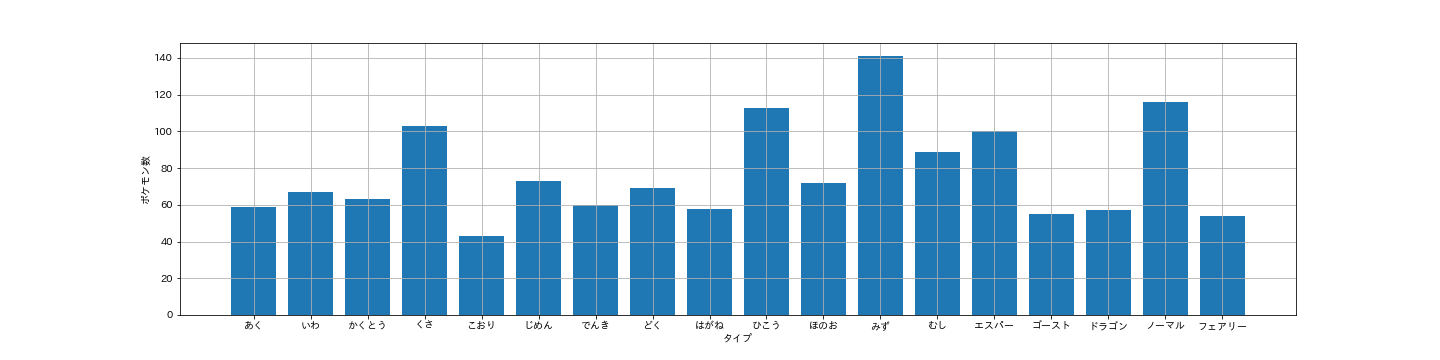
すると、タイプによってデータに含まれるポケモンの数が異なり、データが偏っていることがわかります。この様な偏りのあるデータは不均衡データと呼ばれます。
次に、タイプ毎における能力値パラメータ同士の相関関係と能力値のヒストグラムをプロットします。
相関関係からは能力値同士の関係性が、ヒストグラムからは各々のタイプにおける能力値の分布状況がわかります。seabornライブラリで一気に図示化できます。
#seaborn による タイプ別種族値の統計データのグラフ化
## - 各散布図の対角線にはヒストグラムが表示
fig = plt.figure(figsize=(20,20))
sns.pairplot(df_type, hue='タイプ')
plt.grid(True)
plt.show()
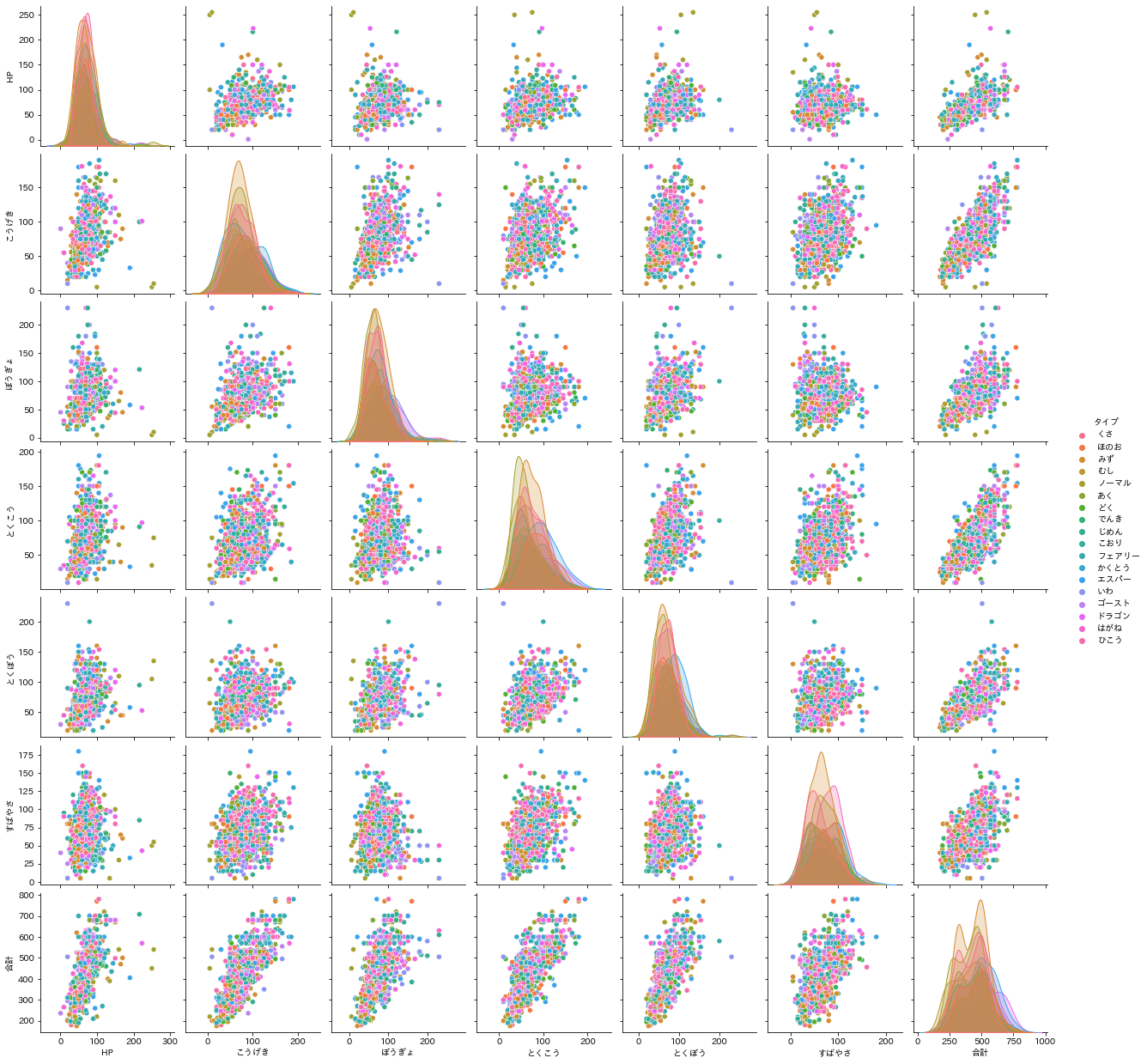
左から右への対角上のグラフがそれぞれの能力値でのヒストグラムを、それ以外は能力値同士の相関関係のグラフになっています。色はそれぞれのポケモンのタイプを表しています。
この色ごとの相関グラフの傾きの違いや、ヒストグラムのピークの位置や幅の違いから、それぞれのタイプでポケモンの区別ができる筈なのですが…
タイプの区別は難しそう
相関グラフの違いは目に見えず、ヒストグラムの違いは目に見えてもそこまで大きくはなさそうです。
というか、みずタイプが非常に多く、他のタイプのヒストグラムがほぼ完全に隠れてしまっています。
これは、ポケモン毎の固有能力値の違いでタイプを区別・推測することが難しいことを示しています。それは機械学習でも同様です。
…果たしてどこまで精度の高いモデルを作成することができるのでしょうか、後半に続く。


