はじめに
Pythonのnetworkxを利用して、twitterのネットワークを題材としたカラフルなネットワークや枝や頂点ごとに太さ大きさが異なるネットワークの可視化方法を紹介します。
networkxの基本的な使い方は、こちら(Pythonのnetworkxで簡単にネットワーク分析)のページで紹介しておりますので、まだの方はご覧ください。
対象ユーザ
- カラフルにネットワークを可視化したい
- 単色の枝や頂点だけでなく、特徴ごとにカラフルなネットワークを描画したい
このようなユーザを対象に、twitterのフォロワーネットワークを使用して、ディスクリプションごとにカラフルなネットワークを描画する方法を紹介します。
twitterのディスクリプションとは?
以下の画像は弊社のTwitterのアカウントのプロフィール画面です。ディスクリプションとは、以下の画像の赤く囲まれている部分であり、ユーザの自己紹介文です。

弊社のTwitterのアカウントはこちらです。
今回は、おまけとして、弊社のフォロワーのディスクリプションを例にして、弊社のフォロワーネットワークはどのようなことに興味があると言えるのか確かめていきます。
ライブラリの読み込み
import pandas as pd
import numpy as np
import networkx as nx
import pickle
import matplotlib as mpl
import matplotlib.pyplot as plt
import japanize_matplotlib
# 自作関数の読み込み
import sys
sys.path.append('../')
from twitter import GetDescriptionNetwork
from twitter import CleansingTweets
from tokenizer import Tokenizer/Users/fuekimasao/.pyenv/versions/anaconda3-2020.02/envs/network/lib/python3.8/site-packages/japanize_matplotlib/japanize_matplotlib.py:15: MatplotlibDeprecationWarning:
The createFontList function was deprecated in Matplotlib 3.2 and will be removed two minor releases later. Use FontManager.addfont instead.
font_list = font_manager.createFontList(font_files)※ 今回は、ネットワーク取得部分のコード(自作関数部分)は詳しく紹介しませんが、この記事に需要があるようでしたら、追記します。
データの取得方法
gn = GetDescriptionNetwork(cleansing=CleansingTweets().cleansing_text,
tokenizer=Tokenizer().mecab_tokenizer,
max_followers=200)
adj_list, users_info = gn.get_network('Deepblue_ts')簡単に説明すると、adj_listがネットワークの元となる隣接リストであり、users_infoがネットワークに所属するユーザの情報です。
len(adj_list), len(users_info.keys())(1128, 1067)上記より、取得したネットワークの枝数が1128本であり、ユーザー数が1067人であることがわかります。
弊社のディスクリプションを分かち書きすると、以下のようになります。
gn.network_keywords['技術', '解析', '取り組む', '戦略', '立案', 'BLUE', 'DEEP', 'AI', '研究開発', '統計', 'ベンチャー企業']簡単ではありますが、ネットワークの取得方法について説明します。
twitter APIを使用して、以下のようにuser networkを取得します。
- 弊社のアカウント(:=root user)のdescriptionをmecabで分かち書きして、list化する
- root userのフォロワー(:=neighbor user)を取得
- neighbor userのうち、共通のdescription wordを持つuserのフォロワーを取得
- 2を複数回行う
※ 共通のdescription wordを持つuserのみ取得したのは、取得するユーザー数が指数的に増加してしまい、取得が終了しないという問題を解決するためです。
データの確認
ネットワーク
今回は、枝に伝播確率のような重みがあることを想定します。(枝重みごとに、枝の太さを変更することが可能なため)
# 枝確率を計算済みのネットワークを確認
network.head()| from_node | to_node | probability | |
|---|---|---|---|
| 0 | Deepblue_ts | gakuseitdn | 0.000771 |
| 1 | Deepblue_ts | minominorin | 0.000489 |
| 2 | Deepblue_ts | vonhathuy | 0.000211 |
| 3 | Deepblue_ts | TruestarCG | 0.002903 |
| 4 | Deepblue_ts | pluefm | 0.012000 |
ユーザ情報
ユーザの情報は、辞書型で格納されており、@から始まるtwitterのscreen_nameを指定することで取り出せます。
# userの情報
user_info['Deepblue_ts']{'id': 1254754340570423302,
'screen_name': 'Deepblue_ts',
'location': '恵比寿',
'url': 'https://t.co/pDaPjaPcCy',
'description': 'Deepblueは統計解析・AI技術による戦略立案・研究開発に取り組んでいるベンチャー企業です',
'description_clean': 'deepblueは統計解析・ai技術による戦略立案・研究開発に取り組んでいるベンチャー企業です',
'followers_count': 48,
'friends_count': 73,
'listed_count': 2,
'favourites_count': 565,
'statuses_count': 39,
'created_at': datetime.datetime(2020, 4, 27, 12, 48, 54),
'elapsed_date': 154,
'favorite_per_day': 3.668831168831169,
'tweet_per_day': 0.2532467532467532}user = network['from_node'][0]
user_info[user]{'id': 1254754340570423302,
'screen_name': 'Deepblue_ts',
'location': '恵比寿',
'url': 'https://t.co/pDaPjaPcCy',
'description': 'Deepblueは統計解析・AI技術による戦略立案・研究開発に取り組んでいるベンチャー企業です',
'description_clean': 'deepblueは統計解析・ai技術による戦略立案・研究開発に取り組んでいるベンチャー企業です',
'followers_count': 48,
'friends_count': 73,
'listed_count': 2,
'favourites_count': 565,
'statuses_count': 39,
'created_at': datetime.datetime(2020, 4, 27, 12, 48, 54),
'elapsed_date': 154,
'favorite_per_day': 3.668831168831169,
'tweet_per_day': 0.2532467532467532}descriptionの単語集合
上記のuserのdescriptionを分かち書きした結果です。
print(gn.network_keywords)['技術', '解析', '取り組む', '戦略', '立案', 'BLUE', 'DEEP', 'AI', '研究開発', '統計', 'ベンチャー企業']シンプルなネットワークの可視化
試しに100本の枝をサンプリングして描画する。一番シンプルなネットワークの可視化です。
G = nx.from_pandas_edgelist(network.sample(n=100),
source='from_node',
target='to_node',
edge_attr=['probability'],
create_using=nx.DiGraph)
plt.figure(figsize=(10, 10))
plt.axis('off')
pos = nx.spring_layout(G, k=0.1)
nx.draw_networkx_nodes(G, pos, node_color="k", node_size=10)
nx.draw_networkx_edges(G, pos, edge_color="c", node_size=10)
plt.show()
※ 見えやすいように、100本の枝のみを描画しています。
小技
dpiを設定することで、高画質な画像を出力やplt.saveや右クリックで保存できます。
plt.figure(figsize=(10, 10), dpi=500)
plt.axis('off')
nx.draw_networkx_nodes(G, pos, node_color="k", node_size=10)
nx.draw_networkx_edges(G, pos, edge_color="c", node_size=10)
plt.show()
枝ごとに太さが異なるネットワークの描画
nx.draw_networkx_edgesの引数:widthに枝の太さを指定するためのlistを与えれば実装できます。
width = [p*100 for _, p in nx.get_edge_attributes(G, 'probability').items()]plt.figure(figsize=(20, 20))
plt.axis('off')
nx.draw_networkx_nodes(G, pos, node_color="k", node_size=10)
nx.draw_networkx_edges(
G, pos, edge_color="c", node_size=10,
width=width)
plt.show()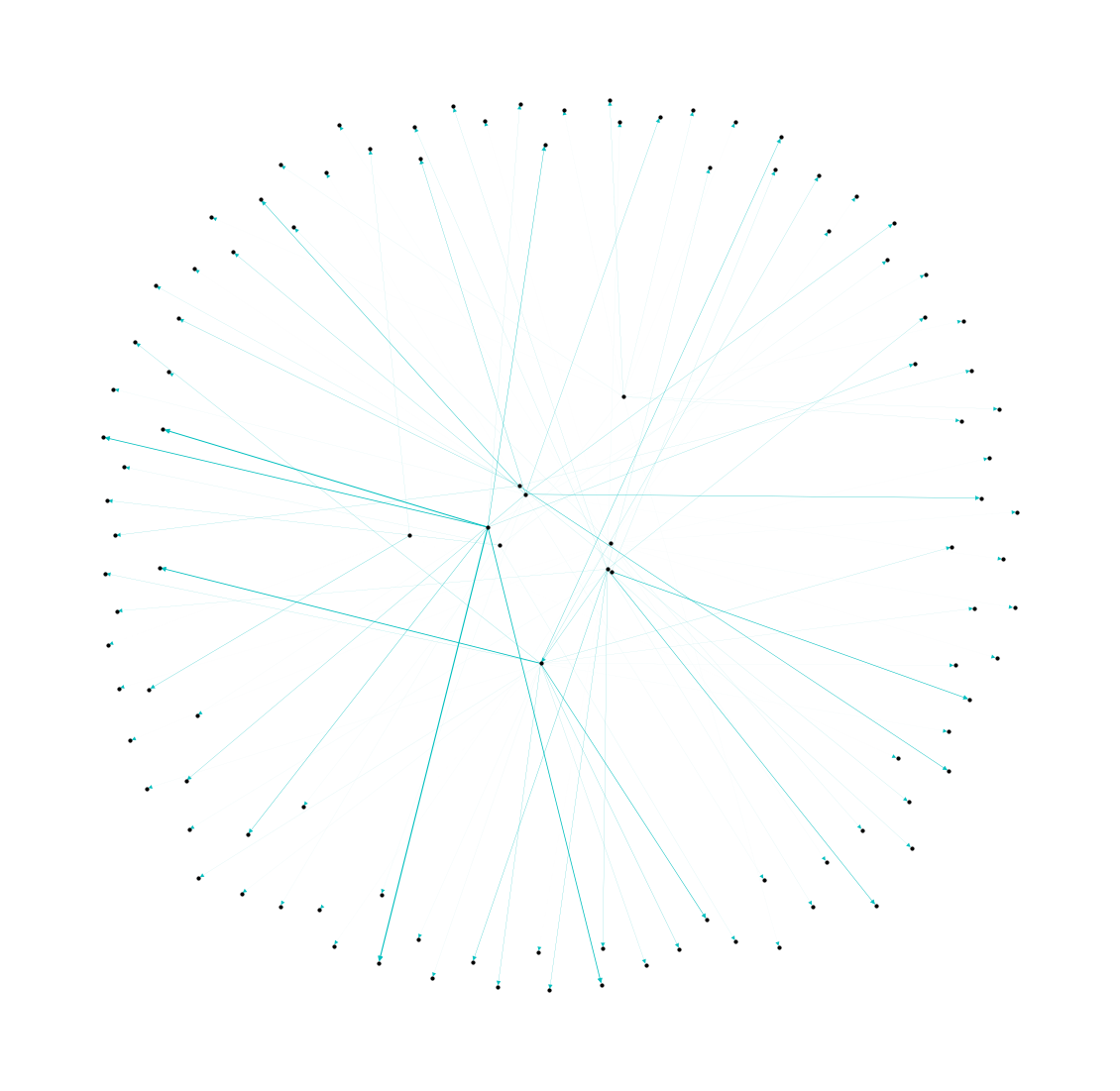
root userと共通単語をもつユーザのみのネットワーク
root userと共通している単語をlink_infoに格納し、共通している単語数をlink_sizeに格納します。
network['link_info']= network.apply(
lambda x: set(gn.tokenizer(user_info[x[0]]['description_clean'])) & \
set(gn.tokenizer(user_info[x[1]]['description_clean'])) & \
set(gn.network_keywords),
axis=1)
network['link_size'] = network['link_info'].apply(lambda x: len(x))
network| from_node | to_node | probability | link_info | link_size | |
|---|---|---|---|---|---|
| 0 | Deepblue_ts | gakuseitdn | 0.000771 | {統計} | 1 |
| 1 | Deepblue_ts | minominorin | 0.000489 | {} | 0 |
| 2 | Deepblue_ts | vonhathuy | 0.000211 | {} | 0 |
| 3 | Deepblue_ts | TruestarCG | 0.002903 | {} | 0 |
| 4 | Deepblue_ts | pluefm | 0.012000 | {AI} | 1 |
| … | … | … | … | … | … |
| 1123 | ai_competition | tnct_science | 0.000446 | {} | 0 |
| 1124 | ai_competition | hait_todai | 0.000050 | {AI} | 1 |
| 1125 | ai_competition | nikunoki | 0.000228 | {} | 0 |
| 1126 | ai_competition | Dream_Lover_Co | 0.000219 | {} | 0 |
| 1127 | ai_competition | at1983xyz | 0.005294 | {} | 0 |
1128 rows × 5 columns
例えば、root userと共通しているuserだけ抽出すると以下のようになります。
network.query('link_size > 0')| from_node | to_node | probability | link_info | link_size | |
|---|---|---|---|---|---|
| 0 | Deepblue_ts | gakuseitdn | 0.000771 | {統計} | 1 |
| 4 | Deepblue_ts | pluefm | 0.012000 | {AI} | 1 |
| 16 | Deepblue_ts | bokuhasumi | 0.000134 | {統計} | 1 |
| 22 | Deepblue_ts | LedgeEngineer | 0.001406 | {AI} | 1 |
| 28 | Deepblue_ts | Cpp_Learning | 0.000804 | {技術} | 1 |
| … | … | … | … | … | … |
| 1117 | ai_competition | rGGTTJdpiEDT4Dv | 0.000996 | {AI} | 1 |
| 1118 | ai_competition | kedbreak136 | 0.000354 | {AI} | 1 |
| 1119 | ai_competition | yousukeigarashi | 0.000045 | {AI} | 1 |
| 1120 | ai_competition | AVILEN_AI_Trend | 0.000116 | {AI} | 1 |
| 1124 | ai_competition | hait_todai | 0.000050 | {AI} | 1 |
111 rows × 5 columns
また、link_infoでフィルターをかけることで、コミュニティ(のような)ネットワークを抽出できます。
network[network['link_info'] == set(['AI'])]| from_node | to_node | probability | link_info | link_size | |
|---|---|---|---|---|---|
| 4 | Deepblue_ts | pluefm | 0.012000 | {AI} | 1 |
| 22 | Deepblue_ts | LedgeEngineer | 0.001406 | {AI} | 1 |
| 244 | pluefm | Deepblue_ts | 0.004110 | {AI} | 1 |
| 245 | pluefm | plue1011 | 0.090000 | {AI} | 1 |
| 249 | LedgeEngineer | aijobcolle | 0.000108 | {AI} | 1 |
| … | … | … | … | … | … |
| 1117 | ai_competition | rGGTTJdpiEDT4Dv | 0.000996 | {AI} | 1 |
| 1118 | ai_competition | kedbreak136 | 0.000354 | {AI} | 1 |
| 1119 | ai_competition | yousukeigarashi | 0.000045 | {AI} | 1 |
| 1120 | ai_competition | AVILEN_AI_Trend | 0.000116 | {AI} | 1 |
| 1124 | ai_competition | hait_todai | 0.000050 | {AI} | 1 |
83 rows × 5 columns
上記のようにフィルターをかけた「AI」のネットワークを描画すると、以下のようになります。
G = nx.from_pandas_edgelist(
network[network['link_info'] == set(['AI'])][['from_node', 'to_node', 'probability']],
source='from_node',
target='to_node',
edge_attr=['probability'],
create_using=nx.DiGraph
)
plt.figure(figsize=(20, 20))
plt.axis('off')
pos = nx.spring_layout(G, k=0.1)
nx.draw_networkx_nodes(G, pos, node_color="k", node_size=1)
nx.draw_networkx_edges(G, pos, edge_color="c",
width=np.array(list(nx.get_edge_attributes(G, 'probability').values()))*80,
node_size=1
)
plt.show()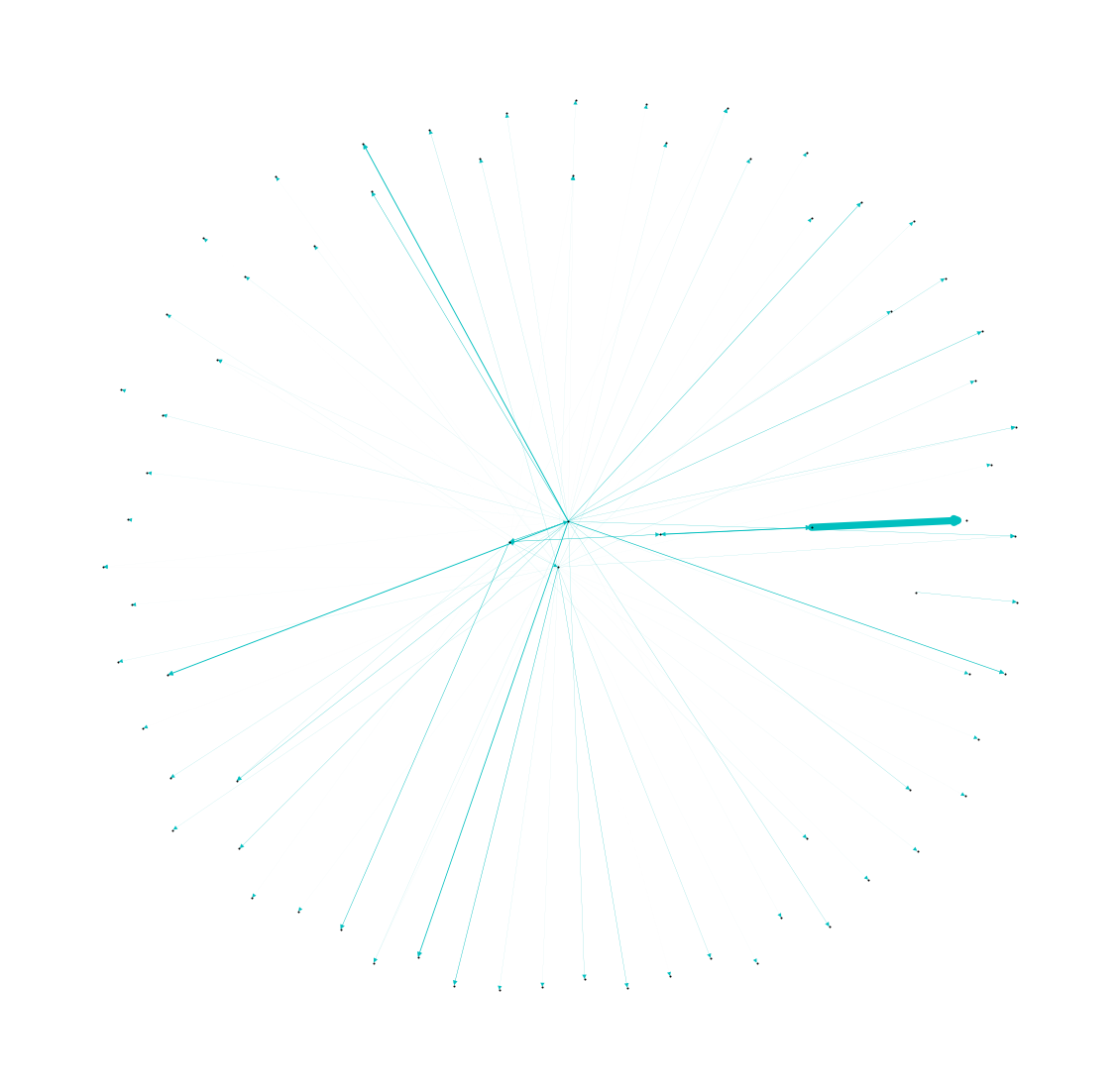
このように描画することで、ユーザ間の関係性がわかりやすく描画できます。
属性ごとに異なる色を着色
ディスクリプション単語ごとに異なる色で枝を描画することを考えます。
G = nx.DiGraph()
link_color_dict = {}
colors = (c for c in plt.cm.get_cmap('tab20').colors)
for u, v ,p, link_info, link_size in network.values:
if link_size > 0:
link_info = tuple(link_info)
color = link_color_dict.get(link_info)
if not color:
color = colors.__next__()
link_color_dict[link_info] = color
G.add_edge(u, v, weight=p, link=tuple(link_info), color=color)以下のように、ディスクリプション単語ごとに色を設定しました
color_list = link_color_dict.values()
tick_label = [','.join(tpl) for tpl in list(link_color_dict.keys())]
plt.figure(figsize=(10, 10))
plt.xticks([])
plt.xlim([0, 1])
x = np.linspace(0, len(color_list), len(color_list))
height = np.repeat(1, len(color_list))
plt.barh(x, height, color=color_list, tick_label=tick_label, align="center")
plt.show()
わかりやすいように、弊社のノードを赤くすることも考えます。さらに、頂点の次数によって、頂点ごとに大きさも設定できるようにします。
node_color = ['r' if node == user else 'k' for node in G.nodes()]
G_degree = nx.degree(G)
node_size = [G_degree[u]*10 for u in G.nodes()]plt.figure(figsize=(20, 20))
plt.axis('off')
pos = nx.spring_layout(G, k=0.1)
nx.draw_networkx_nodes(G, pos, node_color=node_color, alpha=0.6, node_size=node_size)
nx.draw_networkx_edges(G, pos, edge_color=nx.get_edge_attributes(G, 'color').values(),
width=1, node_size=node_size)
plt.show()
このように可視化した結果、全体的に「AI」を共通単語とする枝が多いことがわかります。
実際に、集計して数値として確認すると以下のようになり、実際に、「AI」が多いことがわかります。
df_count = network.copy()
df_count['link_info'] = network.link_info.apply(lambda x: tuple(x))
df_count.groupby('link_info').count()[['link_size']].reset_index().sort_values('link_size', ascending=False)| link_info | link_size | |
|---|---|---|
| 0 | () | 1017 |
| 1 | (AI,) | 83 |
| 4 | (統計,) | 12 |
| 3 | (技術,) | 10 |
| 5 | (解析,) | 5 |
| 2 | (取り組む,) | 1 |
コミュニティの属性絞り込み
共通のディスクリプション単語が「AI」である枝のみを残すと以下のようなネットワークになります。
network[network['link_info'].apply(lambda x: True if 'AI' in x else False)]| from_node | to_node | probability | link_info | link_size | |
|---|---|---|---|---|---|
| 4 | Deepblue_ts | pluefm | 0.012000 | {AI} | 1 |
| 22 | Deepblue_ts | LedgeEngineer | 0.001406 | {AI} | 1 |
| 244 | pluefm | Deepblue_ts | 0.004110 | {AI} | 1 |
| 245 | pluefm | plue1011 | 0.090000 | {AI} | 1 |
| 249 | LedgeEngineer | aijobcolle | 0.000108 | {AI} | 1 |
| … | … | … | … | … | … |
| 1117 | ai_competition | rGGTTJdpiEDT4Dv | 0.000996 | {AI} | 1 |
| 1118 | ai_competition | kedbreak136 | 0.000354 | {AI} | 1 |
| 1119 | ai_competition | yousukeigarashi | 0.000045 | {AI} | 1 |
| 1120 | ai_competition | AVILEN_AI_Trend | 0.000116 | {AI} | 1 |
| 1124 | ai_competition | hait_todai | 0.000050 | {AI} | 1 |
83 rows × 5 columns
G = nx.from_pandas_edgelist(
network[network['link_info'].apply(lambda x: True if 'AI' in x else False)][['from_node', 'to_node', 'probability']],
source='from_node',
target='to_node',
edge_attr=['probability'],
create_using=nx.DiGraph
)
node_color = []
G_degree = nx.degree(G)
for node in G.nodes():
if node == user:
node_color.append('red')
elif 10 < G_degree[node] <= 30:
node_color.append('orange')
elif G_degree[node] > 30:
node_color.append('blue')
else:
node_color.append('k')
G_degree = nx.degree(G)
node_size = [G_degree[u]*30 for u in G.nodes()]
plt.figure(figsize=(20, 20))
plt.axis('off')
pos = nx.spring_layout(G, k=10)
nx.draw_networkx_nodes(G, pos, node_color=node_color, alpha=0.6, node_size=node_size, edgecolors='w')
nx.draw_networkx_edges(G, pos, edge_color='gray', width=1, node_size=node_size)
plt.show()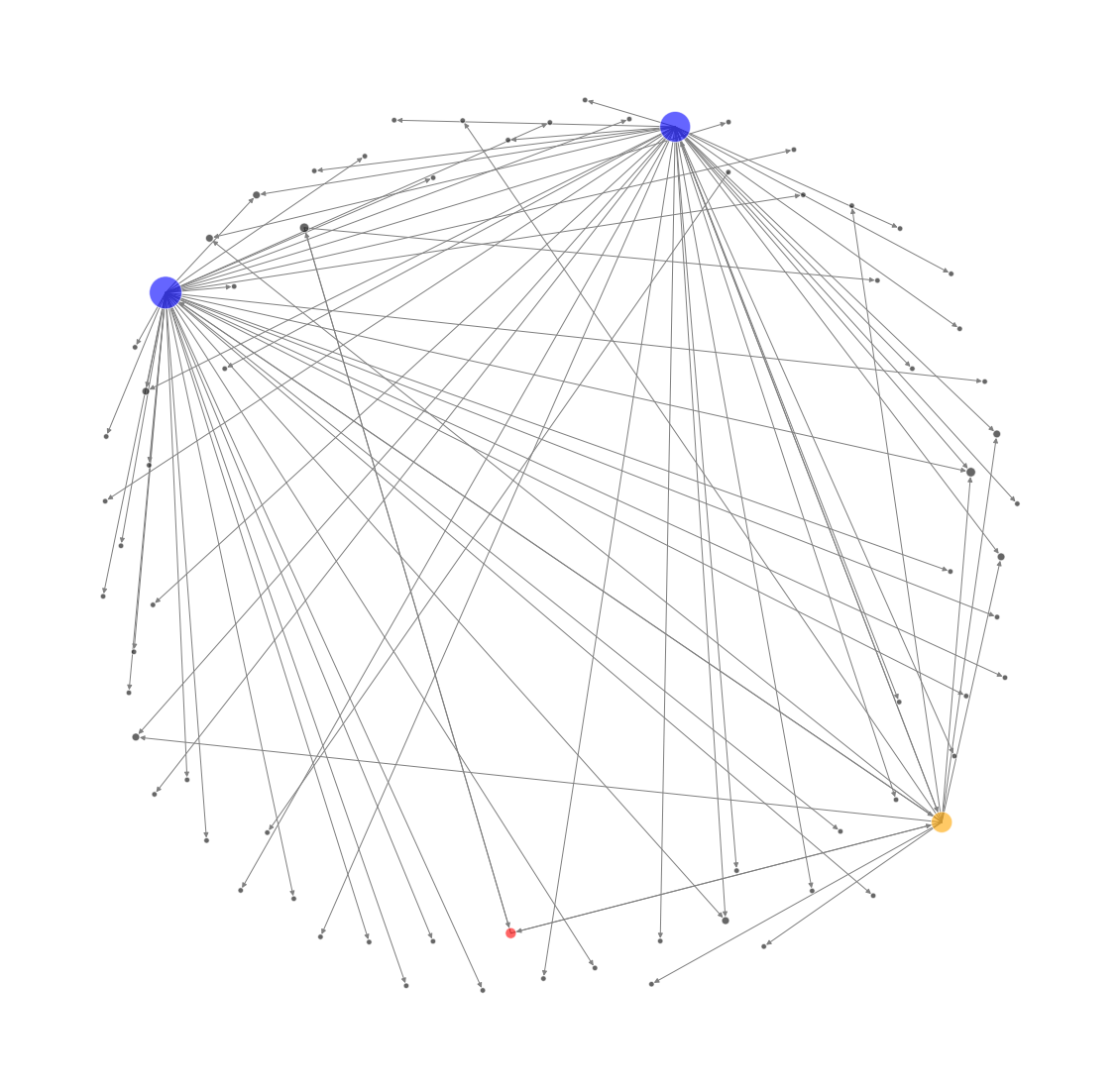
コメント
このネットワークでは、フォロワーの中でも「AI」と言う単語がディスクリプションに含まれているユーザだけが描画されています。
悲しいことに、弊社のアカウント(赤ノード)のフォロワーのうち、「AI」がディスクリプションに含まれているのは、二人しかいません。しかし、一方で、その少ないユーザのうち、オレンジノードのフォロワーには、「AI」がディスクリプションに含まれているユーザーが多く存在していることがわかります。
さらに、オレンジノードのフォロワーのうち、青ノードのように「AI」がディスクリプションに含まれているユーザーがより多く存在しているユーザも出現してきています。
弊社に興味のありそうなユーザとして、オレンジノードや青ノードのフォロワー(「AI」がディスクリプションに含まれている)が考えられそうです。
このようにして、誰をフォローするかやフォロバが返ってきやすいノードは誰かなどのターゲットを効率的に決めることに使えそうです。
まとめ
今回は、カラフルなネットワークを描画するための題材として、twitterのディスクリプションを可視化して、簡単な分析を行いました。