はじめに
この記事は、pythonのmatplotlibを使って棒グラフを描く方法についてまとめたものです。
対象としている読者は、matplotlibを使い始めたばかりの方とします。目標は用意したデータを用いて、軸ラベルや凡例を含めた実践的なグラフを描くことです。
データ分析を行う前に、情報を可視化することは大切だとよく言われます。
今回は、様々な可視化方法の中で最も基本的なものの一つである棒グラフを通じてmatplotlibに慣れることを目的としています。
matplotlibで棒グラフを作成
棒グラフをつくるために必要なものは横軸と縦軸それぞれのデータです。
以下の例ではx軸の値が0, 1, 2 のときに, y軸の値がそれぞれ50, 100, 75 であるような棒グラフを作ります。必要最小限のシンプルなグラフが出力されます。
import numpy as np
import matplotlib.pyplot as plt
# y = [50, 100, 75]
# x = [0, 1, 2]
y = np.array([50, 100, 75]) # y軸のデータ
x = np.arange(len(y)) # x軸のデータ
plt.bar(x, height=y) # 棒グラフを描画
x軸とy軸のデータをリストや配列に入れます。後ほどデータセットを用いたグラフの描き方を紹介しますが、そのデータセットに合わせるためnumpyのarrayオブジェクトを使いました。
それらをpyplotモジュールのbarというメソッドの引数に指定します。必須となる引数はxとheightの二つです。
以上でひとまず棒グラフは描画できました。ここからは必要な情報を追加していきましょう。
引数tick_labelで横軸の値を調整
先ほど出力した棒グラフを見てみましょう。皆さんが普段目にするものと比べて物足りない気がしませんか。グラフのタイトルや軸の名前がありません。
また、横軸の値は0, 1, 2ですが、目盛りが0.5刻みになっていることに違和感を覚える人も多いのではないでしょうか。
これらの調整を行っていきましょう。
まずは横軸を0, 1, 2だけにしてみましょう。以下の例では引数tick_labelを用いて$x$軸の調整をしていますが、pyplotモジュールのxticksメソッドを使っても同じことができます。後に紹介する複数種類のグラフを出力する場合はxticksメソッドの方が便利だと感じます。
barメソッドの引数は他にもたくさんあります。例えばwidthという引数で棒の太さを変更できます。先ほどのグラフでは、引数widthの値について何も指定していないのでデフォルトの0.8になっています。この値を小さくして、細い棒グラフを出力してみます。
import numpy as np
import matplotlib.pyplot as plt
y = np.array([50, 100, 75])
x = np.arange(len(y))
plt.bar(x, height=y, tick_label=x, width=0.4) # 棒のラベルづけと幅の変更
#plt.xticks(ticks=x, labels=x) # 引数を追加せずにこれを書いても良い
plt.show() # グラフを出力
初めに出力されたグラフと比較すると、x軸がすっきりして見やすくなりました。棒の幅も変わっています。
title と label を追加
次にグラフのタイトルと軸ラベルを加えてみましょう。
import numpy as np
import matplotlib.pyplot as plt
y = np.array([50, 100, 75])
x = np.arange(len(y))
plt.bar(x, height=y, tick_label=x)
plt.xlabel('horizontal line') # x軸のラベルづけ
plt.ylabel('vertical line') # y軸のラベルづけ
plt.title('title') # タイトル
plt.show()
軸ラベルとタイトルが加えられていることがわかります。
legendを使って凡例を追加
次に凡例を入れます。凡例とは出力時にグラフを説明する補足のようなものです。
plt.legendを使って凡例を用意します。引数loc=’best’とすると、勝手に凡例をグラフの邪魔にならない位置にに追加してくれます。
import numpy as np
import matplotlib.pyplot as plt
y = np.array([50, 100, 75])
x = np.arange(len(y))
plt.bar(x, height=y, tick_label=x)
plt.xlabel('horizontal line')
plt.ylabel('vertical line')
plt.title('title')
plt.legend(['blue'], loc='best') # 凡例
plt.show()
凡例が右上に追加されたことがわかりますか。
この例だと凡例の良さがわかりにくいので、もう一つの例を紹介します。
import numpy as np
import matplotlib.pyplot as plt
y1 = np.array([50, 100, 75]) # y軸のデータ1
y2 = np.array([30, 25, 75]) # y軸のデータ2
x = np.arange(len(y))
plt.bar(x, height=y1, color='blue') # 青い棒グラフ
plt.bar(x, height=y2, bottom=y1, color='red') # 赤い棒グラフ
plt.xticks(ticks=x, labels=x) # 棒のラベルづけ
plt.xlabel('horizontal line')
plt.ylabel('vertical line')
plt.title('title')
plt.legend(['blue', 'red'], loc='best') # 凡例
plt.show()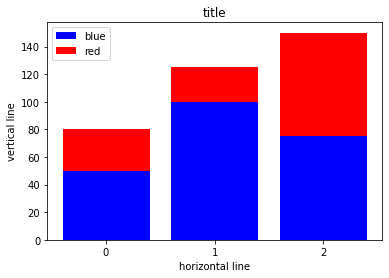
y軸のデータを二つ用意し、縦に並べるような棒グラフを用意しました。y1とy2の色を変えることで、一つの棒に占めるy1やy2の割合がわかりやすくなります。このグラフですと、凡例による説明がなければ青い部分と赤い部分がそれぞれ何を表しているかわかりにくいでしょう。
凡例の位置が一つ前の出力と比べて変わっていることもポイントです。
ここまでで棒グラフの基本についての説明は終わりです。最後にデータセットを使ってグラフを出力する練習を行います。
scikit-learn のデータセットを使って棒グラフを出力
詳しい説明は省きますが、scikit-learnのdatasetsモジュールには様々なデータが用意されています。ここではその中のirisデータセットを使います。
まずはsklearn.datasetsからload_irisをインポートします。
from sklearn.datasets import load_iris
dataset = load_iris()必要に応じてirisデータの中身は確認してみてください。
あとで使うので、以下の例は実行していただきたいです。例えば、カラム名(列名)を調べるときは次のようにします。
dataset.feature_names # 説明変数の変数名['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']目的変数についても調べてみましょう。
dataset.target_names # 目的変数の変数名(略)dataset.target # 目的変数の値(略)numpyのarrayオブジェクトに目的変数の数値が格納されていることがわかります。
これらを参考にすると、目的変数の値、0, 1, 2 はそれぞれ[‘setosa’, ‘versicolor’, ‘virginica’]に対応していることがわかります。
練習してみよう
データセットからグラフを出力する練習をしてみましょう。 2問用意しました。
まずは1問目です。やっていただきたいことは、’setosa’, ‘versicolor’, ‘virginica’がそれぞれいくつあるか調べて、それらの個数を棒グラフにするという問題です。タイトルやラベルなども適切だと思うものを用意してください(正解はないので好きな名前をつけましょう)。
‘setosa’, ‘versicolor’, ‘virginica’それぞれの個数を数える方法が思いつかない人は、少し読み進めて途中からやってみましょう。
それでは少し考えてみてください。一例を下に載せています。
from sklearn.datasets import load_iris
import numpy as np
dataset = load_iris()
count0 = np.sum(dataset.target==0) # 'setosa' の個数
count1 = np.sum(dataset.target==1) # 'versicolor' の個数
count2 = np.sum(dataset.target==2) # 'virginica' の個数‘setosa’, ‘versicolor’, ‘virginica’それぞれの個数を数える方法がわからなかった人もここから少し考えてみてください。
以下に一例の続きを載せています。
plt.bar(x=['setosa', 'versicolor', 'virginica'], height=[count0, count1, count2], width=0.4)
plt.xlabel('target_names')
plt.ylabel('count')
plt.title('dataset_target_count')
plt.show()
ほとんど上で紹介したものと同じになっています。棒ラベルをbarメソッドの引数として指定している点が今までと少し違う点です。どの方法でもできるようにしておきましょう。これで1問目は終わりです。
続いて2問目です。1問目の続きです。’setosa’, ‘versicolor’, ‘virginica’の個数を調べていただきました。それらそれぞれに対して’sepal length (cm) ‘の値が5.5以下になるもの個数を数えてください。その個数を青に、そうでないものの個数を赤にした棒グラフを出力してみましょう。ラベルやタイトル、凡例もつけてみてください。
先ほどと同様に、個数の数え方が思いつかない人は、少し読み進めて途中からやってみましょう。一例を下に載せています。
from sklearn.datasets import load_iris
import numpy as np
dataset = load_iris()
count0 = np.sum(dataset.target==0)
count1 = np.sum(dataset.target==1)
count2 = np.sum(dataset.target==2)
teamA0 = np.sum(dataset.data[dataset.target==0][:,0] <= 5.5) # sepal length の値が5.5以下である'setosa' の個数
teamA1 = np.sum(dataset.data[dataset.target==1][:,0] <= 5.5) # sepal length の値が5.5以下である'versicolor' の個数
teamA2 = np.sum(dataset.data[dataset.target==2][:,0] <= 5.5) # sepal length の値が5.5以下である'virginica'の個数個数を数える方法がわからなかった人もここから少し考えてみてください。
以下に一例の続きを載せています。
y1 = [teamA0, teamA1, teamA2] # sepal length の値が5.5以下であるデータ
y2 = [count0 - teamA0, count1 - teamA1, count2 - teamA2] # sepal length の値が5.5より大きいデータ
x=['setosa', 'versicolor', 'virginica']
plt.bar(x, height=y1, width=0.4, color='blue')
plt.bar(x, height=y2, bottom=y1, width=0.4, color='red')
plt.xlabel('target_names')
plt.ylabel('count')
plt.title('dataset_target_count')
plt.legend(['sepal length (cm) <= 5.5', 'sepal length (cm) > 5.5'], loc='best') # 凡例
plt.show()
2問目は以上です。
練習問題を通して苦手だと感じたものを復習してください。ただし、一部はnumpyやデータセットの扱いに不慣れなことが原因で難しく感じるところもあるので、それらを勉強してからもう一度取り組んでみるのも良いかもしれません。
matplotlibについての練習問題がもっとほしい、という方にはTommyさんのblog記事をやってみることをおすすめします。
可視化の方法は棒グラフだけでなく、ヒストグラムや散布図など多くあります。この記事を読んで棒グラフをスラスラ描けるようになっていれば、関数を変えるだけでそれらを描けるようになっているはずです。ぜひ挑戦してみてください。