どんどん麻雀AIを作ってみよう
親の第一打を推測するモデル
ロン!メンホン一通西してますか?
前々回の記事では、牌姿を画像のように捉え、画像系モデルでよく利用されるCNNを用いて手役を学習させました。
手役を推測する麻雀AI作ってみた
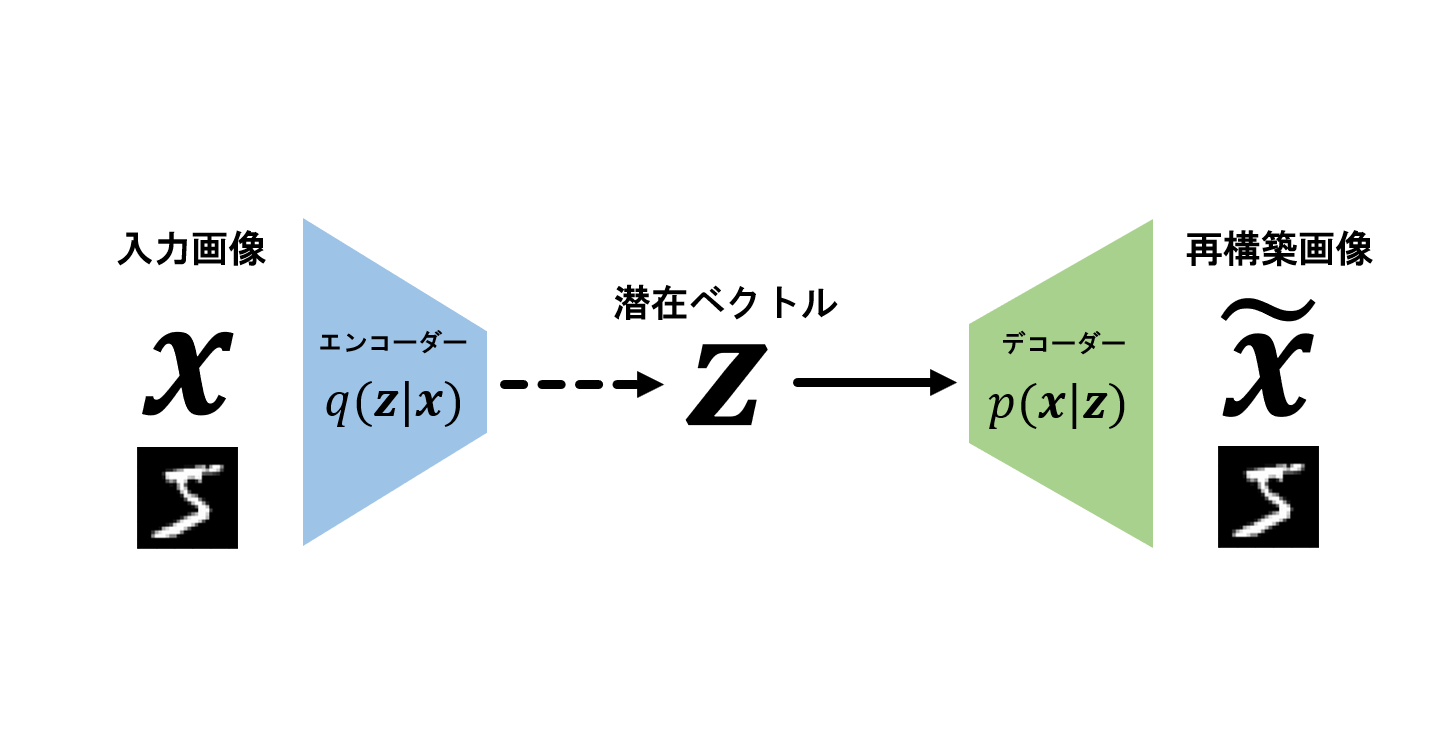
前回の記事では生成系モデルを利用して、配牌からあがりの形を推測するモデルを作ってみました。
あがりの形を推測する麻雀AI作ってみた
麻雀を題材にいろいろなモデルを作ってみましたが、ゲームAIの醍醐味といえばもちろん人間と同じようにプレイをするAIです。やってみましょう!
ポン!チー!カン!リーチ!オリ!点数計算!
……。
いきなり全部は難しいので、一人麻雀(一人でツモと打牌を繰り返してあがりを目指す遊び)のモデルを目指して、親の第一打を予測するモデルでもいいですか?
親の第一打は
- 点数状況にもよるが、親なので攻めたい
- リーチや副露がないので、自分の手牌のみに影響される一打となる
といった特徴があるので、まっすぐにあがりを見た選択になると考えられます。それを繰り返せば一人麻雀を攻略するモデルができそうです。
コード全体は最後にまとめました。
- 環境:Google colaboratory
- 機械学習フレームワーク:Pytorch
インプットデータ
これまでと同様、こちらの記事からデータを利用させていただきました。
【麻雀AI】天鳳鳳凰卓の9年分のプレイをCNNを用いたNNモデルに学習させてみた
少し多めにデータが欲しかったので、2012~2019の天鳳卓のデータから、一局一局の親の第一打を抜き出しました。サンプルサイズは約110万でした。
第一打は端牌と東以外の字牌に偏っています。直感に沿いますね。

毎度のように手牌を多次元情報へ変換します(前回の記事)。今回はシンプルに34種の牌×4枚を用いて1×34×4の三次元テンソルにしました。
モデル自体はそんなに試行錯誤せず、これまでと同様のシンプルなCNNとしました。構造としては画像分類と同じですね。
PyTorchによる多クラス分類の実装
class CNN_mask_2d(nn.Module):
def __init__(self):
super().__init__()
self.relu = nn.ReLU()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=4, kernel_size=(3,1), padding=(2,0))
self.bn1 = nn.BatchNorm2d(4)
self.conv2 = nn.Conv2d(in_channels=4, out_channels=16, kernel_size=(3,1), padding=(2,0))
self.bn2 = nn.BatchNorm2d(16)
self.conv3 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=(3,1), padding=(2,0))
self.bn3 = nn.BatchNorm2d(32)
self.fc = nn.Linear(5120, 34)
def forward(self, input):
x = self.conv1(input)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.conv3(x)
x = self.bn3(x)
x = self.relu(x)
x = x.view(x.size()[0], -1)
x = self.fc(x)
# マスク
x = F.relu(x)
mask, _ = input.max(dim=3)
mask = mask.squeeze()
x = torch.mul(x, mask)
return x
最後の層の後に工夫をしてあります。
打牌候補は潜在的には34種類ありますが、実際には手牌にあるものしか打牌できないので、14種以下です。そこで入力データの三次元テンソルの最後のインプットを34種の牌を枚数から有無に変換することでマスクとして、最終的なアウトプットにかけています。
この処理によって正解率が大きく上がることはありませんでしたが、予測する打牌は手牌の中から選ばれるようになりました。
| tehai_hai_str | dahai_hai_str | predicted_label_str |
|---|---|---|
| [二, 三, 四, 六, 七, 八, ④, 4, 7, 7, 7, 北, 白, 中] | 北 | 北 |
| [五, 六, 八, 八, ②, ③, ⑦, 1, 2, 3, 東, 南, 白, 中] | 白 | 南 |
| [一, 三, 八, 九, ②, ③, ⑥, ⑧, 7, 8, 9, 9, 東, 南] | 南 | 南 |
| [二, 四, ①, ④, ⑤, ⑤, ⑥, 1, 1, 2, 3, 9, 西, 中] | 西 | 西 |
| [三, 七, 七, ⑥, ⑦, ⑨, 6, 8, 東, 南, 北, 白, 發, 中] | ⑨ | 南 |
大体60%くらいの正解率になりました。
ラベル不均衡
打牌ラベルはかなり不均衡なので、勉強ついでに2つの手法を試してみました。
- 少ないラベルに合わせてデータを捨てる
結果、サンプルサイズが減って大幅に正解率が下がりました。 - Focal loss
ラベルが不均衡のデータ向けのFocal lossという損失関数があるそうなので、試してみました。
実装には以下を参考にさせていただきました。
Focal lossの実装(PyTorch)
しかし正解率は下がってしまいました……。
今後一人麻雀をするモデルを作る上でも、字牌を切るべき手牌は字牌を切る判断を正確にしてほしいので、ラベルの不均衡については何も処理をしないことにしました。
コード全部
一人麻雀モデルを作ってみよう?
字牌が大半を占めていることで思ったよりいい結果を出せているように見えます。
そこで、次はこのモデルをもとに、強化学習を使って一人麻雀であがりを目指すモデルを作ってみたい!……のですが、なかなか進んでいません。上手く行けば、また次回!