日本では2020年4月7日に7都府県に対し緊急事態宣言を行い、4月16日に対象を全国に拡大しました(5月25日に解除)。また記事執筆時(2021年3月現在)も二度目の緊急事態宣言真っ只中です。今回はこの緊急事態宣言がコロナ対策の政策としてどれほど有効なのかを統計学的に考えていきます。
0.手法の検討
効果検証の各手法については
を参考にしています。効果検証入門に関する記事はこちら。
Rでデータを観察していきましょう。データはこちらから入手可能です。
2020年3月6日から8月31日までのデータを使うこととします。データフレームをRのtsオブジェクトに加工し、PCR検査人数および陽性患者数の推移とその周波数スペクトルをプロットすると、以下のようになります。
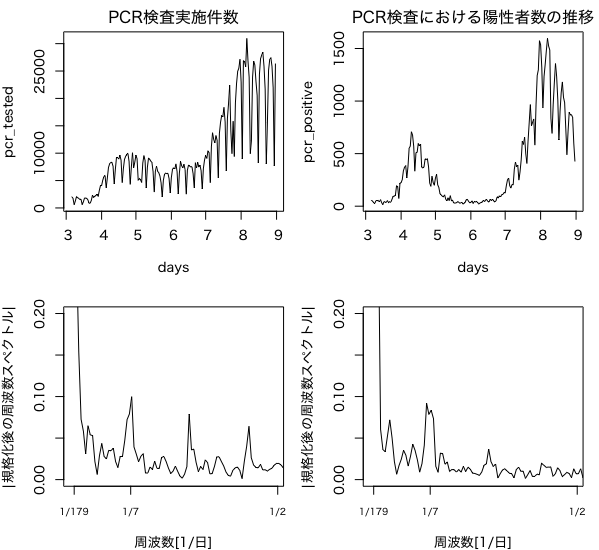
陽性者数の推移を見ると、緊急事態宣言期間中の4月中旬から5月末にかけて大幅な減少が見られ、「緊急事態宣言の効果で陽性者数が減少した」と結論付けたくなってきます。しかし、この期間のPCR検査実施件数を見るとこれも緊急事態宣言期間中に減少していることが確認できます。ゆえ、期間中の陽性者数の減少は単にPCR検査の数を減らしたことが原因かもしれません。このような共変量の影響を排除して純粋な介入効果を探るのが効果検証です。
では手法を検討していきます。最初は4月7日~16日の宣言が限定的に実施された期間に着目し、宣言を行った地域とそうでない地域を比較するDID法を考えましたが、期間が短すぎることや良いデータが入手できなかったことから却下しました。そこで今回は、状態空間モデルを使ってPCR検査数を考慮した緊急事態宣言の効果を分析します。
さらにグラフを見ると、検査数および陽性患者数は7日の周期があることもわかります。そこで、「ローカルトレンド+周期+回帰」というモデルを作ります。
1.検証
- モデルをdlmの関数を使って定義
- データからパラメータを最尤推定
- フィルタリング
- 平滑化
- 効果の検証
という順序で進めていきます。
1.1モデルの定義
Rのdlmパッケージを使ってカルマンフィルタを実装していきます。
library(dlm)
#---
# モデル選択、パラメータの特定----
#---
# 観測値と説明変数を用意
interve_start = '2020/4/7'
interve_end = '2020/5/25'
y = pcr_positive
x_dash_tested = pcr_tested
x_dash_interve = rep(0, length(days))
x_dash_interve[which(days == interve_start):which(days == interve_end)] = 1
x_dash = ts.union(x_dash_tested, x_dash_interve)
# モデルの定義
build_dlm_COVID19 = function(par){
return(
dlmModPoly(order = 2, dW = exp(par[1:2]), dV = exp(par[3])) +
dlmModSeas(frequency = 7, dW = c(exp(par[4]), rep(0, times = 5)), dV = 0) +
dlmModReg(X = x_dash, addInt = FALSE, dW = c(exp(par[5:6])), dV = 0)
)
}
# パラメータの特定
fit_dlm_COVID19 = dlmMLE(y = y, parm = rep(0, 6), build = build_dlm_COVID19)
mod = build_dlm_COVID19(fit_dlm_COVID19$par)モデルを定義し、パラメータの最尤推定量を求めることができました。
1.2 フィルタリング
フィルタリングを行い、成分ごとにプロットしていきます。
#---
# フィルタリング----
#---
dlmFiltered_obj = dlmFilter(y = y, mod = mod)
m = dropFirst(dlmFiltered_obj$m[,1])
s = dropFirst(dlmFiltered_obj$m[,3])
beta_tested = dropFirst(dlmFiltered_obj$m[,9])
beta_interve = dropFirst(dlmFiltered_obj$m[,10])[which(days == interve_start):which(days == interve_end)]
# 成分のプロット
oldpar = par(no.readonly = T)
par(mfrow = c(2,2))
par(oma = c(0, 0, 0, 0))
par(mar = c(4, 4, 2, 1))
par(family = "HiraginoSans-W4")
plot(days, m, type = 'l', main = 'レベル成分')
plot(days, s, type = 'l', main = '周期成分')
plot(days, beta_tested, type = 'l', main = '検査数の効果')
plot(days[which(days == interve_start):which(days == interve_end)],
beta_interve,
type = 'l', main = '介入効果',
xlab = '介入期間',
ylab = 'beta_interve')
par(oldpar)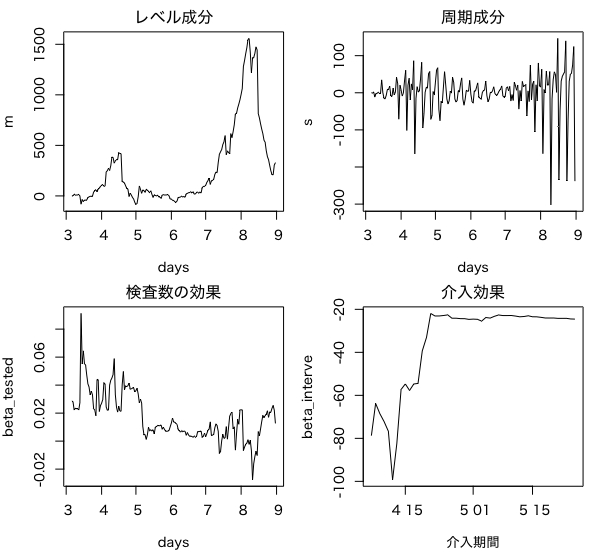
時系列データを各成分に分けることができました。
1.3平滑化
つぎに、フィルタ分布を元に平滑化を行います。フィルタリングでは過去と現在までの情報に基づいて推定を行っていたのに比べ、平滑化では相対的な未来の情報も考慮して推定を行うため、一般に予測精度は向上します。
#---
# 平滑化----
#---
dlmSmoothed_obj = dlmSmooth(y = y, mod = mod)
m_smooth = dropFirst(dlmSmoothed_obj$s[,1])
s_smooth = dropFirst(dlmSmoothed_obj$s[,3])
beta_tested_smooth = dropFirst(dlmSmoothed_obj$s[,9])
beta_interve_smooth = dropFirst(dlmSmoothed_obj$s[,10])[which(days == interve_start):which(days == interve_end)]
# 成分のプロット
oldpar = par(no.readonly = T)
par(mfrow = c(2,2))
par(oma = c(0, 0, 0, 0))
par(mar = c(4, 4, 2, 1))
par(family = "HiraginoSans-W4")
plot(days, m_smooth, type = 'l', main = 'レベル成分')
plot(days, s_smooth, type = 'l', main = '周期成分')
plot(days, beta_tested_smooth, type = 'l', main = '検査数の効果')
plot(days[which(days == interve_start):which(days == interve_end)],
beta_interve_smooth,
type = 'l', main = '介入効果',
xlab = '介入期間',
ylab = 'beta_interve')
par(oldpar)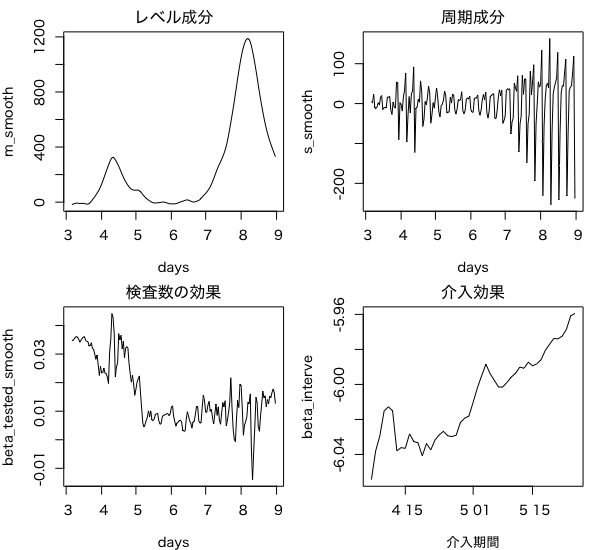
レベル成分がフィルタ分布の時よりも滑らかになっています。
2.効果の検証
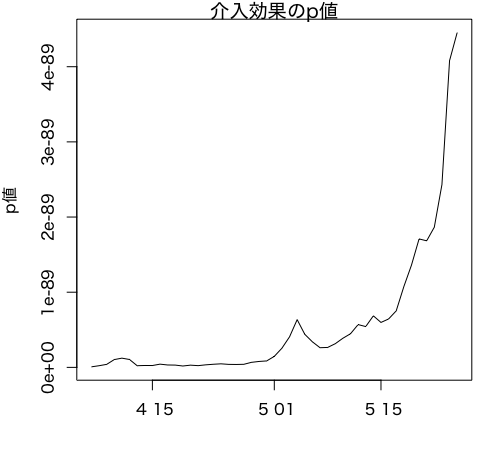
0か1の値しか取らない介入変数を導入した回帰を行うことによって、介入効果を測ることができます。グラフより、緊急事態宣言によって陽性患者数を1日に6人程度減らせる負の効果があったことがわかります。以下のようにp値をプロットすることで、統計的に有意な効果も確認できます。時間を通じて介入効果は有意に存在するようです。
3. 終わりに
今回は、PCR検査の陽性者数のデータを用いて検査数という共変量を除いた時の緊急事態宣言の効果を検証しました。単純なモデルを用いたことや、共変量を一つしか設定していないことなど、まだまだ改善点は多いため、さらに手法を勉強した上でまた検証して見たいと思います。最後までお読みいただきありがとうございました。

![[Rによる演習付き]操作変数法を理解する](https://blog.deepblue-ts.co.jp/wp-content/uploads/writing-828911_1920.jpg)