本記事ではTensorFlow 2.0 の使い方を初心者向けに解説しています。
TF2をコーディングするにあたって最低限知っておくべき書き方をセレクトして解説しているのでTF1のコーディングしたことあるけど
TF2はないよという方も参考になると思います。 是非目を通してみてください。
実行環境はGoogle Colabを想定しているのでTF2のインストールは済んでいるものとします。
また、ディープラーニングについての原理や理論にはこの記事では扱わず、実装することでこの世界に慣れていくというスタンスでやります。
TensorFlow 2.0 とは
TensorFlow
はGoogleを中心に深層学習向けに現在も開発されているオープンソースプラットフォームで現在世界で最も利用されているフレームワークだと言われています。似たフレームワークとしてPytorchなどがあります。
TensorFlow 2.0が 2019年10月 正式リリースされ、まだ日が浅いため既存のコードのほとんどTF1で記述されているという状況です。
使いやすさも汎用性の高さもこれからはTF1よりTF2なので、
これから入門する人はTF2から始めることがおすすめです。
TF1からTF2への主な変更点
TF1からTF2への変更点として大きく三つの点があります。
- Eagar Mode(動的計算グラフ)がデフォルトになる いつくかの変更点の中でも一番の大きな変更点だと思います。
- keras APIとの統合 Kerasが、TF標準の高レベルAPIになることで、TF2は格段に読みやすいコーディングが可能になりました。
- 重複したAPIを整理
動的グラフといえばPytorchでしたが、ついにTensorFlowでもデフォルトとして採用されました。tf.functionの静的グラフへの変換がすごい。
TF 1.x時代のtf.Sessionやtf.placefolderなどいつくかの高レベルAPIが使用不可となりました。
TensorFLow 2ではTensorFlowとKerasを組み合わせてコーディングしているようなイメージです。
もちろん、TensorFlowのみKerasのみでモデルの構築から学習まで完結できるのですが、
モデルの構築はKeras(tf.keras)で書き、モデルの学習はTensorFlow(tf.GradientTapeなど)で行うという流れを意識しましょう。
| フレームワーク | 主な特徴 | メリット |
|---|---|---|
| TensorFlow 1 |
静的計算グラフ |
計算速度が高速 |
| PyTorch |
動的な計算グラフ オブジェクト指向 自然言語処理などでよく使われる |
デバッグがしやすい 容易に複雑なネットワークを実装できる Numpyと似たような操作方法ができる |
| Keras |
静的な計算グラフ 人間にとって分かりやすい設計 オブジェクト指向(なコーディングもできる) |
表現したいネットワークを実装するの早い ユーザーフレンドリー CPUやGPU上でシームレスな動作 |
| TensorFlow 2 |
動的な計算グラフ TF1とKerasを組み合わせたインターフェース オブジェクト指向(なコーディングもできる) |
計算速度が高速 ユーザーフレンドリー 容易に複雑なネットワークを実装できる Numpyと似たような操作方法ができる |
TF1からTF2へアップデートされたことで上記3つのフレームワーク(TensorFlow1, Pytorch,Keras)のいいところ取りしているようなAPIになりました。(PyTorchも素晴らしいライブラリーだと思います)
TensorFlow 2.0 での tf.function と AutoGraph
ディープラーニング のフレームワークの計算グラフはネットワークを構築する種類は大きく2つあります。
- Define-and-run(静的計算グラフ) フレームワーク : TensorFlow1.x, Keras など
- Define-by-run(動的計算グラフ) フレームワーク : PyTorch, Chainer, TensorFlow2.x など
メリット : 動的グラフと比べて計算が高速
デメリット: 言語処理や音声処理が苦手
メリット : 計算結果を確認できるためデバッグしやすい
デメリット: 静的グラフと比べて計算が低速
動的グラフと静的グラフの主な違いはグラフを構築するのがグラフを定義したときなのか、順伝搬が発生したときなのかです。
TensorFlow1.xはDefine-and-run(Graph mode)という静的計算グラフをデフォルトしていましたが、 Define-by-run(Eagar mode)の動的計算グラフをデフォルトとするPyTorchの実装能力と汎用性の高さから、Graph ModeからEager Modeへのデフォルト化となりました。
いまいちピンと来ないかもしれませんが
パラメータを生成するのにコンパイルをしなければならない静的グラフはプログラマにとって都合が悪いということなのでしょう。
TF2 では動的計算グラフ(Eagar Excecution)の直感的なインターフェースとTF1(Graph mode) の計算速度を両立させる tf.function という素晴らしい機能があります。これは ほとんどのPython の構文で利用可能で@tf.functionとアノテーションを付け加えるだけでハイパフォーマンスな TensorFlow のグラフ(tf.autograph)に変換してくれます。
詳しく知りたい方は
TensorFlow 2.0 での tf.function と AutoGraph
を参照してください。
Python と TensorFlow のバージョン確認
# python3.6 バージョン確認
import sys
print(sys.version)
# TF2.xの読み込み
import tensorflow as tf
# バージョンの確認
print('TensorFlow version: {}'.format(tf.__version__))3.6.9 (default, Apr 18 2020, 01:56:04)
TensorFlow version: 2.2.0
PythonやTensorFlow 2のインストールは済んでいるものとします。
実行環境はGoogle Colabです。TensorFlow がバージョン2以上であることを確認しましょう。
画像データの読み込む (MNIST)
# MNISTデータセットを使用
mnist = tf.keras.datasets.mnist
(x_train, t_train), (x_test, t_test) = mnist.load_data()
# 0~1へ正規化する
x_train, x_test = x_train / 255., x_test / 255.
print(x_train.shape, x_test.shape, t_train.shape, t_test.shape)Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] – 0s 0us/step
(60000, 28, 28) (10000, 28, 28) (60000,) (10000,)
画像データセットは
tf.keras.datasetsからダウンロードできます。前処理として0~1に正規化しています。
TensorFlow 2.0 API コーディング方法
TensorFlowのコーディング方法は大きく分けて3つあります。- Sequential API (初心者向き)
- Functional API (中初級者向き)
- Subclassing API (エキスパート向き)
| TF2.x API | こういう方におすすめ | メリット | デメリット |
|---|---|---|---|
| Sequential API |
初心者 とりあえずニューラルネットワークを試す方 |
初心者でもモデルの構築から学習まで容易 グラフ構造を可視化可能 |
分岐するネットワークの構築ができない |
| Functional API |
初中級者 Kerasユーザー 複雑なネットワークを構築したい方 |
複雑なネットワークを構築可能 グラフ構造を可視化可能 |
動的なモデルを実装できない |
| Subclassing API |
中級者以上 PyTorchユーザー 日常的にTFを使いこなしたい方 |
フルカスタマイズ可能 動的なネットワークを構築可能 |
APIの学習コストが高い グラフ構造を可視化が難しい |
Kerasの使用経験がある方はSequential APIとFunctional APIから入門するのがおすすめです。
PyTorchの使用経験がある方はSubclassing APIから入門するのがおすすめです。
Sequential API (初心者向き)
Sequential APIってどんなもの?
- 各層の入力テンソルと出力テンソルが1つの最もシンプルなAPIです。分岐のないネットワークを構築できます(VGGネットワークなど)
- Kerasユーザーなら分かると思いますが、ほとんどKerasと同じ感覚で実装できます。
- 静的なグラフ構造でモデルをコンパイルしたときパラメータを生成します。
- モデルの保存はSavedModel形式がおすすめです。一定間隔でモデル保存したいときはCheckpointという形式でも保存可能です。
実装手順
- モデルの構築(
tf.keras.models.Sequential)
→リストにレイヤーを積み重ねることでモデル構築します。 -
モデルのコンパイル(
model.compile)
→最適化関数と損失関数を選択し計算グラフを構築します。 -
モデルを訓練(
model.fit)
→エポック数とバッチ数を指定してトレーニングします。 -
モデルの評価(
model.evaluate)
→オプションですが、verboseでプログレスバーを出力できます。 -
モデルの保存(
tf.saved_model)
→model.saveでSavedModel形式で保存することができます。
難しいと感じるのは最初だけなので、初心者の方は根気強くAPIを見ながらコードをトレースしてください。
さらに詳しく知りたい方は
tf.keras.Sequential
を参考にしましょう。
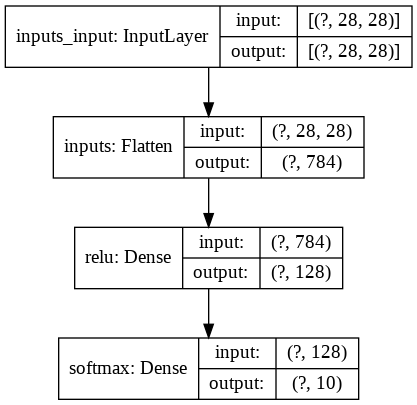
# 1.モデルの構築
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28), name='inputs'),
tf.keras.layers.Dense(128, activation='relu', name='relu'),
tf.keras.layers.Dense(10, activation='softmax', name='softmax')
], name='Sequential')
# 2.モデルのコンパイル
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 3.モデルの学習
history = model.fit(x_train, t_train, epochs=5, batch_size=32)
# 4.モデルの評価
model.evaluate(x_test, t_test, verbose=1)
# 5.モデルの保存(シリアル化)
model.save('Sequential_model')
# モデルの読み込み
model_load = tf.keras.models.load_model('Sequential_model')
# グラフの可視化
tf.keras.utils.plot_model(model, to_file='Sequetial.png', show_shapes=True)Epoch 1/5 1875/1875 [==============================] – 3s 2ms/step – loss: 0.2540 – accuracy: 0.9275
Epoch 2/5 1875/1875 [==============================] – 3s 2ms/step – loss: 0.1121 – accuracy: 0.9661
Epoch 3/5 1875/1875 [==============================] – 3s 2ms/step – loss: 0.0780 – accuracy: 0.9760
Epoch 4/5 1875/1875 [==============================] – 4s 2ms/step – loss: 0.0582 – accuracy: 0.9823
Epoch 5/5 1875/1875 [==============================] – 3s 2ms/step – loss: 0.0447 – accuracy: 0.9866
313/313 [==============================] – 0s 1ms/step – loss: 0.0749 – accuracy: 0.9765
INFO:tensorflow:Assets written to: Sequential_model/assets
Functional API (中初級者向き)
Functional APIってどんなもの?
- 共有レイヤーを持つモデルや複数の入力または出力を持つモデルを扱うことができます。。Sequential APIより柔軟性の高いモデルです。
- Sequenal APIと同じで、ほとんどKerasと同じ感覚で実装できます。
- 大体のモデルは実装できると思います。inceptionネットワークなどを実装してみるとFunctional APIの練習になるかなと思います。
- 静的なグラフ構造でモデルをコンパイルしたときパラメータを生成します。
- モデルの保存はSavedModel形式がおすすめです。一定間隔でモデル保存したいときはCheckpointという形式でも保存可能です。
実装手順
- モデルの構築(
tf.keras.models.Sequential)
→リストにレイヤーを積み重ねることでモデル構築します。 -
モデルのコンパイル(
model.compile)
→最適化関数と損失関数を選択し計算グラフを構築します。 -
モデルを訓練(
model.fit)
→エポック数とバッチ数を指定してトレーニングします。 -
モデルの評価(
model.evaluate)
→オプションですが、verboseでプログレスバーを出力できます。 -
モデルの保存(
tf.saved_model)
→model.saveでSavedModel形式で保存することができます。
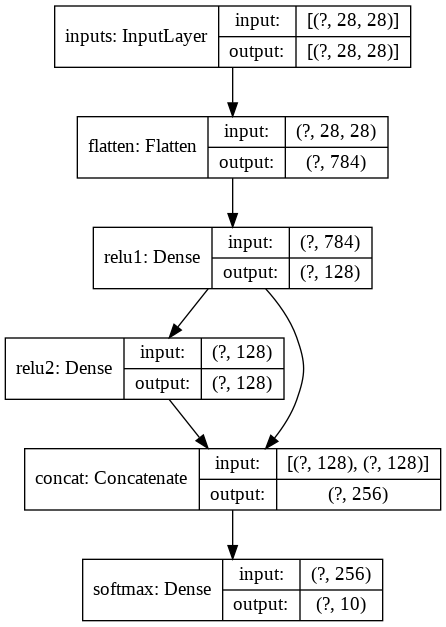
# 1.モデルの構築
inputs = tf.keras.layers.Input(shape=(28, 28), name='inputs')
flatten = tf.keras.layers.Flatten(name='flatten')(inputs)
hidden1 = tf.keras.layers.Dense(128, activation='relu', name='relu1')(flatten)
hidden2 = tf.keras.layers.Dense(128, activation='relu', name='relu2')(hidden1)
concat = tf.keras.layers.Concatenate(name='concat')([hidden1, hidden2])
outputs = tf.keras.layers.Dense(10, activation='softmax', name='softmax')(concat)
model = tf.keras.models.Model(inputs=inputs, outputs=outputs, name='functional')
# 2.モデルのコンパイル
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 3.モデルの学習
history = model.fit(x_train, t_train, epochs=5, batch_size=32)
# 4.モデルの評価
model.evaluate(x_test, t_test, verbose=1)
# 5.モデルの保存(シリアル化)
model.save('Functional_model')
# グラフの可視化
tf.keras.utils.plot_model(model, to_file='Functional.png', show_shapes=True)Epoch 1/5 1875/1875 [==============================] – 4s 2ms/step – loss: 0.2298 – accuracy: 0.9328
Epoch 2/5 1875/1875 [==============================] – 4s 2ms/step – loss: 0.0953 – accuracy: 0.9708
Epoch 3/5 1875/1875 [==============================] – 5s 2ms/step – loss: 0.0674 – accuracy: 0.9781
Epoch 4/5 1875/1875 [==============================] – 4s 2ms/step – loss: 0.0494 – accuracy: 0.9843
Epoch 5/5 1875/1875 [==============================] – 4s 2ms/step – loss: 0.0401 – accuracy: 0.9871
313/313 [==============================] – 0s 1ms/step – loss: 0.0769 – accuracy: 0.9774
INFO:tensorflow:Assets written to: Functional_model/assets
Subclassing API (エキスパート向き)
Subclassing APIってどんなもの?
- カスタマイズ性が最も高く自由にモデル構築ができる点で最もおすすめするAPIです。
- モデルの定義をオブジェクト指向に定義するためPyTorchに似ている
Subclassing APIのモデル学習方法の書き方は2種類あります。
カスタマイズ性が高いのは②学習方法(テープによる学習)ですがコーディング方法は色々知っておいた方がいいのでどちらも押さえておきましょう。
①学習方法(デフォルトのメソッドで学習)
- モデルの定義(
tf.keras.Model)
→クラスの定義しtf.keras.Modelを継承させます(PyTorchに似てる) -
モデルのコンパイル(
model.compile)
→最適化関数と損失関数を選択し計算グラフを構築します。 -
モデルを訓練(
model.fit)
→エポック数とバッチ数を指定してトレーニングします。 -
モデルの評価(
model.evaluate)
→オプションですが、verboseでプログレスバーを出力できます。 -
モデルの保存(
tf.saved_model)
→model.saveでSavedModel形式で保存することができます。
②学習方法(テープによる学習)
- モデルの定義(
tf.keras.Model)
→クラスの定義しtf.keras.Modelを継承させます(PyTorchと記述方法が似てる) - パラメータを更新する関数の定義(
tf.GradientTape)
1ステップ分更新します。@tf.functionとアノテーションすると高速です - 最適化関数、損失関数、評価指標の定義(
tf.keras.optimizers、tf.keras.losses、tf.keras.metrics)
→tf.keras.Modelのようにクラスを継承してカスタムレイヤを定義することもできます。 - モデルを訓練(関数化しておくと便利)
→エポック数とバッチ数を指定してモデルを訓練します。 -
モデルの評価
→バッチ数を指定してモデルを評価します。 - モデルの保存(
tf.saved_model)
→model.saveでSavedModel形式で保存することができます。
TF2のコーディング方法を学ぶのはどんな書籍よりもTensorFlowの公式のチュートリアルが一番わかりやすいです。
もっと知りたいと思った方は エキスパートのための TensorFlow 2.0 入門 を参照してください。紹介しているコードも参考にしています。
1. モデルの定義(tf.keras.Model)
PyTorchのようにモデルをクラスで定義してtf.keras.Modelを継承させます。
イニシャライザ : __init__()
モデル生成された時実行されます。tf.keras.layersを定義することが多いです。
メソッド : call()
__call__を呼び出されたときに実装されます。__call__は関数っぽく呼び出したら発動します。PyTorchでいうforwardのことです。
# Subclassing APIはclassで定義する
class SubClassing(tf.keras.Model): # tf.keras.models.Modelでも可
# モデル生成された時実行される
def __init__(self):
# super(クラス名, self).__init__() 親クラスの継承
super(SubClassing, self).__init__()
# tf.keras APIでレイヤーを定義
self.flatten = tf.keras.layers.Flatten()
self.hidden = tf.keras.layers.Dense(128, activation='relu')
self.outputs = tf.keras.layers.Dense(10, activation='softmax')
# __call__()で呼ばれるメソッド (PyTorchでいうforward)
def call(self, x):
# Functional APIのように記述できる
x = self.flatten(x)
x = self.hidden(x)
return self.outputs(x)2. パラメータを更新する関数の定義(tf.GradientTape)
パワメーターを1ステップ分更新する関数を定義します。
作成した関数に@tf.functionという静的なグラフへ変換するデコレータをアノテーションするのがおすすめです。
下記に示すtrainのようなEpochを回す関数にアノテーションさせ高速化させることもできます。
ですがエラーが発生するとデバッグが難しいので以下のように実装しておくと安全です。
# tf.functionでグラフへコンパイルする
@tf.function
def train_step(images, labels):
# with内部の勾配を計算
with tf.GradientTape() as tape:
# モデルの前進処理
logits = model(images)
# 損失の計算
loss_value = loss_object(y_true=labels, y_pred=logits)
# 損失に対する勾配を求める
grads = tape.gradient(loss_value, model.trainable_variables)
# 指定した最適化関数を用いてモデルの更新(zipを忘れないように注意)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# 訓練の損失を記録 train_lossグローバル変数
train_loss(loss_value)
# 訓練の正答率を記録 train_accuracy グローバル変数
train_accuracy(y_true=labels, y_pred=logits)
# tf.functionでグラフへコンパイルする
@tf.function
# 微分はせずのモデルの評価をするとき使用する
def test_step(images, labels):
# モデルの前進処理
predictions = model(images)
# 損失の計算
t_loss = loss_object(labels, predictions)
# テストの損失を記録 test_lossグローバル変数
test_loss(t_loss)
# テストの正答率を記録 test_lossグローバル変数
test_accuracy(labels, predictions)3. 最適化関数、損失関数、評価指標の定義(tf.keras.optimizers、 tf.keras.losses、tf.keras.metrics)
最適化関数、損失関数、評価指標のインスタンスを生成しています。モデルのクラスで継承させたようにこれらはカスタムレイヤーとして実装することができます。
モデルの複雑になると必須となるテクニックとなると思います。
カスタムレイヤーについて詳しく知りたい方はカスタムレイヤーを参照してください。
# 損失のインスタンスの生成
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
# 最適化関数のインスタンスの生成
optimizer = tf.keras.optimizers.Adam()
# 訓練の損失を記録するインスタンスの生成
train_loss = tf.keras.metrics.Mean(name='train_loss')
# 訓練の正答率を記録するインスタンスの生成
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
# テストの損失を記録するインスタンスの生成
test_loss = tf.keras.metrics.Mean(name='test_loss')
# テストの正答率を記録するインスタンスの生成
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')4. モデルを訓練(関数化しておくと便利)
train(モデル, 訓練データ, テストデータ, エポック数, バッチサイズ)とするのがわかりやすいと思います。
tf.data.DatasetというのはPyTorchでいうDataLoaderです.
静的グラフに変換することで高速化するようです。
関数trainと関数train_step両方にtf.functionのアノテーションをするとエラーが発生するので気をつけてください。
この実装では損失や最適化関数はグローバル変数として定義していますが、Trainerクラスなど定義して制御してもオブジェクト指向でみやすいコーディングができるかもしれません。
# model.fitに代わる関数
# @tf.function デバッグが難しい
def train(model, x_train, t_train, epochs, batch_size):
# tf.dataに変換 PytorchでいうDataLoader
ds_train = tf.data.Dataset.from_tensor_slices((x_train, t_train)).shuffle(10000).batch(32)
# Epoch回train_stepで訓練する
for epoch in range(epochs):
# 自動でシャッフルしてバッチ処理
for ds in ds_train:
train_step(ds[0], ds[1])
# 訓練履歴の出力
template = 'Epoch {}, Loss: {}, Accuracy: {}'
tf.print(template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100))
# 訓練履歴のリセット
train_loss.reset_states()
train_accuracy.reset_states()
# モデルインスタンスの生成
model = SubClassing()
# モデルの訓練 引数としてエポックとバッチサイズを与えるようにすると便利
train(model, x_train, t_train, epochs=5, batch_size=32)Epoch 1, Loss: 0.2591005861759186, Accuracy: 92.52999877929688
Epoch 2, Loss: 0.18625375628471375, Accuracy: 94.6191635131836
Epoch 3, Loss: 0.14942409098148346, Accuracy: 95.64777374267578
Epoch 4, Loss: 0.12630699574947357, Accuracy: 96.29499816894531
Epoch 5, Loss: 0.10968343913555145, Accuracy: 96.76700592041016
5. モデルの評価
モデルの評価を行います。訓練データだけだと過学習している可能もあるので必ず訓練に使われていないデータでモデルの評価を行うようにしましょう。
# tf.dataに変換 PytorchでいうDataLoader
ds_test = tf.data.Dataset.from_tensor_slices((x_test, t_test)).shuffle(10000).batch(32)
for ds in ds_test:
test_step(ds[0], ds[1])
template = 'Loss: {}, Accuracy: {}'
print(template.format(test_loss.result(),test_accuracy.result()*100))Loss: 0.07085442543029785, Accuracy: 97.7699966430664
6. モデルの保存(tf.saved_model)
基本的にはモデルの保存はmodel.saveでできると思います。
モデルが複雑になり、保存にエラーが出るときは具象関数(テンソルの形状を指定するなど)というのを調べてみましょう。
具象関数についてはConcrete functionsを参照してください。
# 5.モデルの保存(シリアル化)
model.save('Subclassing_model')
# モデルの読みこみ
model_load = tf.saved_model.load('Subclassing_model')INFO:tensorflow:Assets written to: Subclassing_model/assets
まとめ
いかがだったでしょうか?TF1.x系でのtf.placeholderやtf.Session変数の初期化等で挫折してしまった人も少なくないと思います。TF2.0になってコード量が少なくなるしNumpyのようなテンソル操作ができる人ならなんとなくわかるようなインターフェースになっており好印象です。PyTorchやTF1では個人的にkerasに比べると入門しにくい感があり、ディープラーニング のおすすめのフレームワークと言いにくかったのですが、TF2.0になって自信を持ってオススメできるようになりました。
本ブログでTensorFlowユーザーがより増えると幸いです。
好評だったらTFに関する別記事あげる予定です