こんにちは、人間です。色々 (Google Colab のコンピュータユニットが枯渇してGPU使用不可だった・自然言語処理に浮気) あって時間が空いてしまったのですが、やっと及第点レベルのネコチャンが生成できました。
この記事は前編 の続きです。こちらを読んだ方がわかりやすいかもしれません。
前編のおさらい
敵対的生成ネットーワーク (GAN) とは深層学習の学習手法の一つです。
その内容は簡単にいうと、「生成画像と本物を正確に識別することを目的とするモデル(識別器)」と「識別モデルすらも騙す画像を生成することを目的とするモデル(生成器)」を敵対させ合うことで、画像生成・識別モデルを学習させる方法です。
本記事では、猫の「こてつ」君の自作データセットを使用して GAN で猫の画像生成モデルを作成しようとしました。
が、しかし結果は以下の通り…

(※注 : 前編時点で一番マシなネコチャンの生成画像です)
_人人人人人人人人人人人人人人人人人_
> なんか溶けた茶色みたいなのがいる!? <
 ̄Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y ̄
これは… ね…こ…? いや、少なくとも猫だとは判別できないです、人間の目では。
なぜうまくいかないのかの仮説
非常に冗長になるので詳細は省きますが、前編のブログ記事の執筆時点で、ハイパーパラメータの調節や生成器・識別器の学習回数の調節などによる GAN の精度の向上を試みていました。
しかし、前編以上の精度にはなりませんでした。
また、上記のマシな生成画像を眺めているとあることに気づきました。それは、
- GANの典型的な失敗例である「モード崩壊」が起きてない
- 「フローリング・絨毯の床・机」等の背景と中心にいる「猫の様な何か」の境界ははっきりとしている ( = 生成モデルは中央に茶色の物体があることは認識している)
です。要するに、真ん中の何かがボヤけてよくわかんないだけで学習そのものが全くできていないわけではないということが言えます。
この事から、モデルやハイパーパラメータとは別の部分に上手くいかない重大な要因があるのでは…と仮説を立てられます。もっと具体的に言えば、そもそも自作したデータセットが良くないのではないかと…。
猫データセットはGANに向いた画像データセットではない?
以上の仮説を基に、GAN系の論文でよく使用される CelebA データセットとのサンプル同士の比較を行うことで、自作の猫データセットの問題点を考察しました。
まず、双方のデータセットの一部サンプルを並べたものが以下の図です。

この二つのデータセットのサンプル同士を比較すると、CelabA は総じて 顔が中心に写っているのに対して、猫データセットは基本的に全身を、しかもポージングや向きが異なり顔が写ってすらいない画像すらあります。
この事から、データセットに起因するGANの失敗要因として以下の二点が考えられます。
- 元々が「全身」の画像である為、64*64 にリサイズする際に頭のパーツが潰れてしまい、猫の特徴をGANが学習できない
- その為、猫の顔や耳などの特徴が反映されない
- バッチ内の各画像の平均値で最適化されるために、「バッチ内の全猫のポージング・向きの平均値」を学習・生成してしまう
- その為、「猫の様な茶色の何か」として平均値が出力された
猫データセットの改良
以上の仮説を基にして、猫データセットの画像に以下の加工を施しました。
- 猫の顔が写っていない画像はデータセットから取り除く
- 猫の顔が画像の中心になる様にトリミングを行う
この仮説が正しければ、データセットに起因する失敗要因が無くなるので DCGAN の学習や生成画像が良くなる筈です。

改良したデータセットでのDCGANの試行
パラメータ設定
以上の改良したデータセットを使用して改めてDCGANの学習を行いました。学習するにあたって、モデルのパラメータをとりあえず前編同様に設定しています。
| パラメータ名 | 値 |
|---|---|
| 訓練時に実行するエポック数 | 400 |
| 訓練に使用するバッチサイズ | 4 |
| 生成器・識別器を伝播する特徴マップの深さ | 64 |
| 潜在ベクトルの要素数 | 100 |
| 生成器・識別器の学習率 | 0.0002 |
Adam (生成器・識別器) のハイパーパラメータ1 (beta_1) |
0.5 |
Adam (生成器・識別器) のハイパーパラメータ1 (beta_2) |
0.999 |
データセット内の画像は改良によって 500 枚に減りました。
学習の結果
(1) 各エポックにおける損失と画像の識別確率
まずは各エポックにおける損失・正解率から学習の様子を確認します。この学習による各エポックにおける生成器・識別器の損失(左)と、本物画像と生成画像の正解と識別する確率(右)は以下の様になりました。
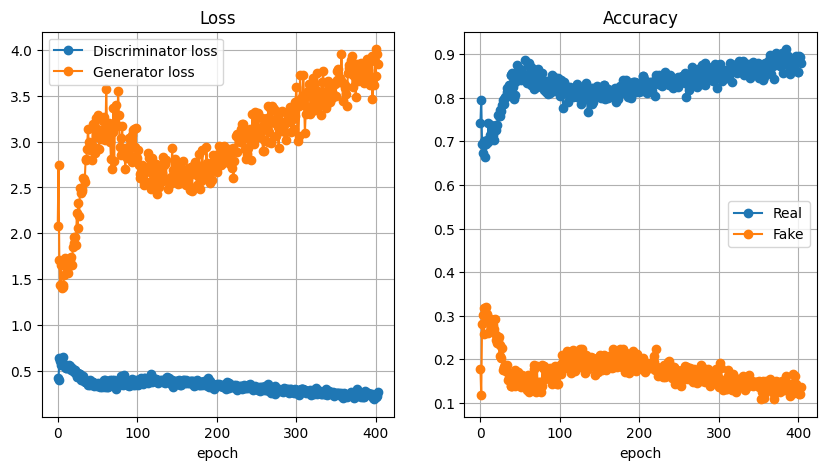
図のとおり、終始生成器の損失が識別器よりも大きく、生成器が不利な状態であること・生成画像と本物画像の識別がかなりはっきりできていることがわかります。
しかし、
- 0~150 エポックの間に、生成器の損失が減少する期間がある
- 150 エポック以降は一方的に生成器の損失が上がり続けている
という特徴が見られている為、最初の150エポック頃までは生成器の学習が上手くできていたが、それ以降は生成器・識別器の学習のバランスが完全に崩壊して学習がうまく進まなくなった のだろうことが読み取れます。
(2) 各エポックにおける生成画像
次に各エポックにおける生成画像から生成器の学習の様子を見ていきます。学習の序盤・中盤・終盤における代表的な生成画像として以下の生成画像が得られました。
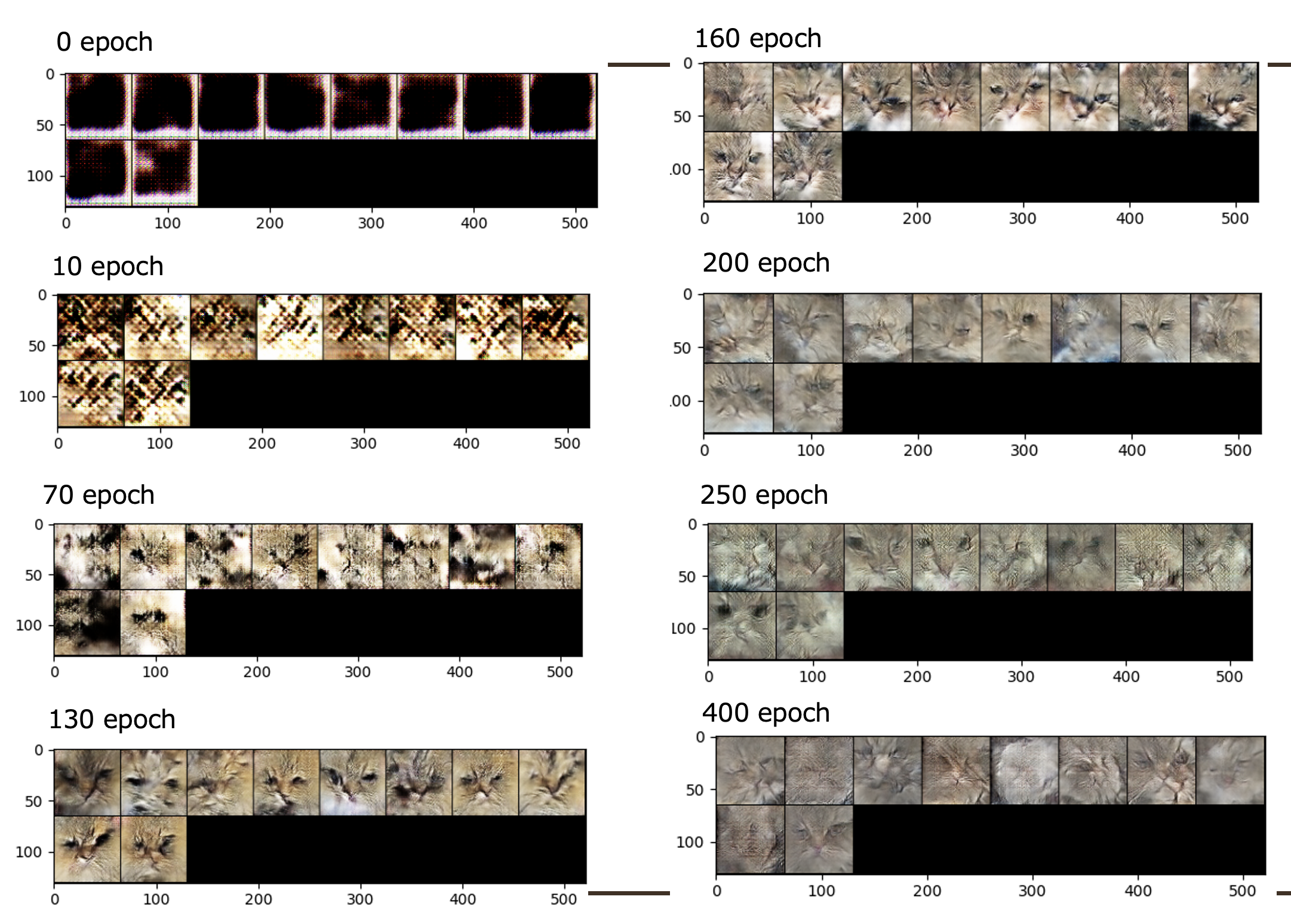
この生成画像より、最初は段々と猫の特徴(目・鼻・口・白とトラ柄の毛色)を反映できており、130 エポックで最も「本物のネコチャンらしい」画像が生成できる様になっていることがわかります。少なくともデータセット改良前よりは「猫だ」と人間の目でも判断できるでしょう。
しかし、それ以降は段々と色や造形が歪んでしまっていることがわかります。
生成画像が歪み出すタイミング (130 エポック以降) は、生成器の損失が一方的に上がり始めて学習バランスが完全に崩壊しだしたタイミングと一致しており、このことから学習バランスが崩れた後も学習し続けると正しい学習ができず台無しになってしまうことが言えます。
まとめと感想 : 猫データセットの改良によってより良いネコチャンの画像を生成できた!
以上の結果より、データセット内の画像の改良によって、よりネコチャンらしい画像を生成できる様になったことが示されました。
即ち、「前編のネコチャン画像生成 GAN でうまく猫が生成できなかったのは、そもそも自作猫データセットが悪かったから (全身・ポーズが不定) なのではないか」 という仮説は概ね当たっているという結論に帰着しました。
しかし、生成器が識別器に拮抗できずに最後には学習バランスの崩壊が起きてしまった為、まだ「如何に学習バランスを長く保たせて生成器を洗練させるか」という課題が多く残っています。
それこそ、「ハイパーパラメータの調節」や「生成器・識別器の学習回数の調節」等の学習を安定化させるテクニックを用いて試行錯誤する必要があるでしょう。
今後も Google Colab のコンピュータユニットと時間の余裕があれば、色々上記試行錯誤を重ねてモデルのブラッシュアップをしていきたいと思います。