atmaCupってなに?
あーとましてますか?
atmaCup(あーとまかっぷ)とは日本で開催される機械学習のコンペティションの一つです。決められた課題を予測するモデルの性能を競います。海外だとkaggle、日本だとSIGNATEなどが有名ですね。
atmaCup#10は初心者向けのコンペだそうです。本当でしょうか。機械学習コンペってなんだか怖くないですか。kaggleは本を一通り写経してTitanicをサブミットした程度の初心者なのですが。いじめられたりしないんですか。
何をしたの?何をすればいいの?
-3日前
業務を調整しよう!!!
atmaCup#10は8日間の短距離走です。業務が大変にならないよう調整しましょう(それができれば苦労はない)。
0日目(開始)
開会式を見ました。今回のお題はアムステルダム国立美術館の作品につく「いいね!」数を予測するコンペだそうです。典型的なテーブルデータの他、作品の説明文、代表色を表すデータなどが与えられるようです。なんだか楽しそうですね。
とりあえずエクセルでデータを眺めてみますが何もわからん……初心者向け講座が解説されるまで待とう……と思ったら早速LighGBMのbaselineのコードが投稿されていたのでコピペで投稿してみます。噂の「緑の画面」を確認することができました。atmaCupではスコアが改善すると緑の画面が褒めてくれるのです。

これはdescriptionの言語処理を入れた直後の提出です。爆上がり。
1~2日目
土日はずっと色の特徴量と戯れていましたがほぼ徒労に終わりました。目が覚めると特徴量のことを考えており完全に中毒になっています。
それから初心者向け講座#1を拝聴します。データフレームにどう関数を使っていけばいいのか全くわかってなかったので大いに勉強になりました。
アイディア管理をカンバンボードにするといいと聞いたので(この勉強会での覚えたての知識)、片っ端からカードを作っていきます。
これは終わった後の状態なのできれいに片付いています。よかったですね。
3~5日目
業務が忙しかったので横目でディスカッションを眺めていました。言語処理が盛り上がっているようです。
os.path.joinについて議論、添削してもらっているこのディスカッションを見て地味に感動しました。初心者が知りたいのってこういうことだったりしませんか?
6日目
時間ができたので初心者向け講座#2を睨みながらコードを整理します。
その後、腹をくくってタイトルと説明文の言語処理に手を出しました。開始早々にBERTを利用しためちゃくちゃ立派なコードが投稿されていたのですが、一応言語処理の勉強中の身なので自前で特徴量を用意しました。
7日目
会社の人もあーとましてくれると言うのでチームを組みました。なんとハイパラ調整を全部やってくれました。今回その辺は捨てる気でいたのでありがたいです。でも今回はLightGBM一強だったのであまり効きませんでした。
あとは噂に聞くアンサンブルとやらも奏でられて満足です。
8日目(最終日)
最後に気になってたテーブルだけ手を付けて、カンバンボードがきれいになったので終わりにしました。パブリックの順位は41位。上位15%には入っているし、スコアも当初の目標の1.0を切ったので初参加にしては頑張ったのではないでしょうか。
ところでここらでベストスコアが再現できなくなり、今更実験管理のディスカッションを読みました。次からはちゃんとやります。すいません。
せっかくなので閉会式をリアルタイムで見守りました。プライベートのリーダーボードがじわじわ上に上がっていきます。大きな波乱も予想されていませんが25位を過ぎてもちっとも我々のチームが出てきません。
……見逃した……?もしかして上位15%からも落ちてる……?
あっ!
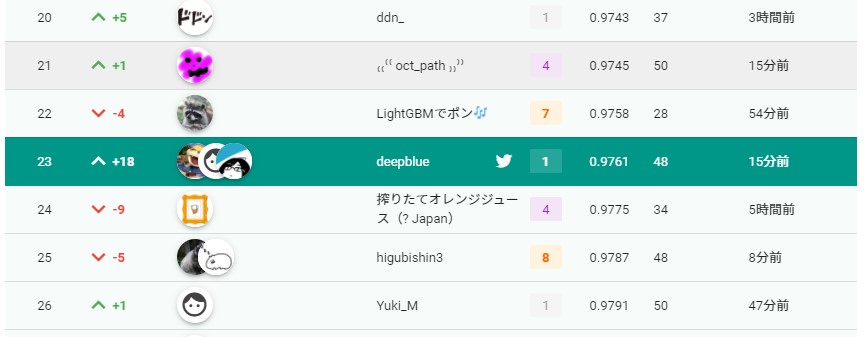
↑18で23位フィニッシュだ!
うっ、嬉しい……。楽しい……。atmaCup最高……。
9日目(その後)
ディスカッションにどんどん人の解法が出ているので、面白くてどんどん読みます。
23rd solution
加減がよくわからなかったのでとにかくLightGBMに特徴量をいれまくりました。最終的にカラムは230個くらいになりました。以下代表的な特徴量です。
- 言語処理(title, descriptionに対して)
- 単語長
- textheroで前処理の後、出てくる単語すべてをオランダ語のfasttext学習済みモデルで特徴量変換して総和を取り、50次元に圧縮
- タイトル言語
- 色(palette, colorはどちらも利用)
- RGB, HLSの平均値
- ratioの最大値と標準偏差
- 低評価の絵について2次元のPCAをfitさせて全体にtransformしたときのPC1, PC2の平均と標準偏差(単色の絵とカラフルな絵の差を出したかった)
- メインのテーブルから作者、サブタイトルから抽出した作品サイズ、年代など
- technique, material, object_collectionなどの他テーブルについては適宜Count encoding、またはOne-hot encoding
勝因はディスカッションを丁寧に読んだこととビギナーズラック(ニューラルネットワークがあまり効果がなかったところなどは初心者に追い風だったような)という感じですが、BERTに頼らずここまで登れたのは嬉しいですね。
atmaCup#10は初心者歓迎の名に偽りない楽しいコンペでした。君もatmaCupで俺と勝負!
Header photo by Rembrandt Harmenszoon van Rijn on Rijksmuseum