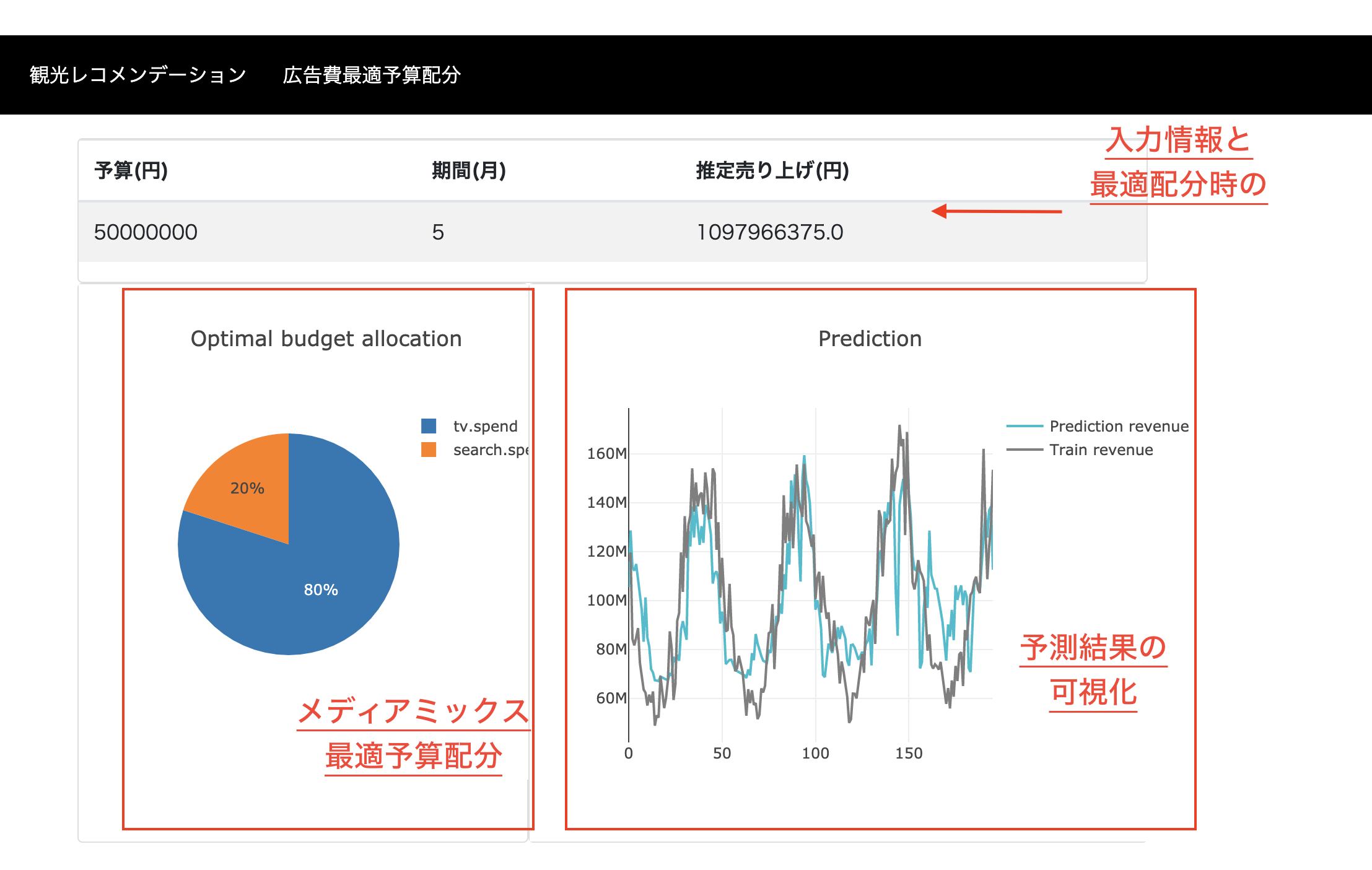
J-QuantsAPIを用いて株式分析チュートリアルを動かしてみた。
はじめに
みなさん、こんにちは!
今回は、J-QuantsAPIを使用して株式市場をデータ分析してみませんか?という内容となっています!
筆者は、データ分析はやったことあるけど、金融知識はゼロ、、、といった人間です。いつものように、今回は何を分析しようか、と企んでいたときに発見したのが株式分析チュートリアルです。
今回は、このチュートリアルを使用して、ChatGPTとJ-Quants APIを用いながら、株式市場の分析に取り組みました。初学者なりに解釈して得た知見・困難を共有していきたいと思います!
株式分析チュートリアルについて
はじめに、株式分析チュートリアルについて、簡単に紹介します。
株式分析チュートリアルとは、SIGNATEが過去に開催した2つのコンペティションのために、日本証券グループが作成したチュートリアルです。チュートリアルでは、株式市場分析におけるデータサイエンスの活用方法について、基本から実践的な手法まで、網羅的に説明されています。
また、初学者にも配慮された設計で、重要なドメイン知識の説明や、陥りやすいミスについて記述されており、非常に充実した内容となっていました!
現在、コンペティションに参加することはできませんが、J-Quants APIを通してデータを取得することにより、チュートリアルを動かすことができます!
株式分析チュートリアルの実行とChatGPTとの共同作業
実際にチュートリアルを進める中で、チュートリアル内のコードが、現行のAPIと対応していない部分があります。
しかしながら、J-Quants APIに対応した、株式分析チュートリアルの実行モデルが、すでに開発されており、github上に公開されております。
大変ありがたいですね。筆者も、ノートブックを大いに参考にさせていただきました。開発・提供してくださったAlpacaJapan様に深く感謝しています。
AlpacaJapan様はもとより、データサイエンスと金融マーケットのコミュニティであるMarket API Developer Community(マケデコ)を運営されております。このコミュニティはJ-Quantsはもちろんのこと、データサイエンスと金融マーケットについての知見を共有する場となっています。そのため、みなさんも是非、マケデコのDiscordに参加することをお勧めします!
また、株式分析チュートリアルに加え、コンペティションで準優勝したUKI様の決算評価モデルも参考にさせていただきました。深く感謝しています。
さて、APIの正式版は直近でも何度かバージョンアップさているため、上記のノートブックを参考にしつつ、それらに対応するためにChatGPT-4を用いながら動かしました。主な使用方法については以下となります。
- クラス・関数名の提案
- エラー修正
- データの可視化
- 新しい手法の提案
- コード作成
- コードの説明・コメントアウト
なお、ChatGPTを使用する際、ワークスペースを何度も変更してしまったため、全ての会話記録は公開できませんが、その一部はこちらより確認できます。実感として、コーディングに割く時間が半分ほどになったと感じております。
また、分析の際に使用したコードはこちらより確認できます。
ファンダメンタルズ分析チャレンジ
続いて、株式分析チュートリアルが解説している、2つのコンペティションの概要について紹介したいと思います!
株式分析チュートリアルは、ファンダメンタルズ分析チャレンジとニュース分析チャレンジの2つのコンペティションについて解説されています。
ニュース分析チャレンジは、ファンダメンタルズ分析チャレンジのモデルをベースとして作成する、といった流れになります。
今回の記事では、主にファンダメンタルズ分析チャレンジを紹介したいと思います!
ファンダメンタルズ分析チャレンジは、上場企業の銘柄情報・株価情報・ファンダメンタル情報等を駆使し、東証上場企業の決算短信発表後、20営業日の間における当該企業の株価の最高値及び最安値を予測するタスクとなっています。
ターゲット
それでは、ファンダメンタルズ分析チャレンジのチュートリアルを、実際のプロセスに沿って見ていきましょう!
はじめに、ファンダメンタルズ分析では何を予測するのかをしっかりと把握しましょう! というのも、筆者が最初につまずいた点が、ターゲット(目的変数)です。株価の高値と安値の予測にあたって、ターゲットは株価そのものだと思い込んでいましたが、今回のチャレンジでは株価そのものはターゲットとして設定されていませんでした。
調べてみたところ、株価それ自体をターゲットにすると、分析は上手くワークしないといいます。というのも、株価をはじめとした時系列データは非定常過程、つまり、時間が経つにつれて平均やばらつきなどが一定でない、変わってしまうようなデータの過程を持つそうです。
このような場合、例えばデータ分析の代表的な手法である回帰分析は、時系列データの分析には適していません。そこで時系列データの解析には、「(弱)定常性」という仮定を置くことが必要となります。
今回のコンペティションでは株価の最高値及び最安値への変化率をターゲットと設定していました。つまり、決算短信発表後の基準日の終値を1としたとき、翌日以降の、20営業日間における最高値や最安値がそれに対する増加・減少分を表す指標、つまり決算の良し悪しを表す指標ということが分かりました!
{(基準日付の翌日以降20営業日間における高値or安値)/(基準日付の終値)} – 1
ということで、果たして、今回のターゲットが(弱)定常性となっているのかを確認してみました。
以下の図は、東京証券取引所のプライム市場における、ターゲットを時期ごとに区分し、ヒストグラムとカーネル密度関数をプロットしたものです。
この図から、ターゲットは、時期が変わったとしても分布が概ね変わっていないように見受けられます。つまり、ターゲットが(弱)定常過程でありそうだ、と考えられるわけです。

ここで、「わざわざターゲットを一工夫した指標にしなくてもいいんじゃないの?」と思う方がいるかも知れません。
例えば、「終値のとる数値の範囲は銘柄ごとに違うから、機械学習がワークしないだけで、標準化や正規化をすれば解決するのでは?」と。筆者もこのような考えを持っていましたが、「定常性」という観点では、標準化や正規化には注意が必要となります。
この理解を深めるために、以下のグラフを作成しました。
このグラフは、2021年4月から7月の、プライム市場における終値のデータを用いて平均と標準偏差を求め、それらを2021年4月から2022年4月のデータに適用して標準化したときのグラフです。
つまり、「2021年7月までのデータしか持っていない」と仮定したとき、未来に対しても同じような分布が期待できるのか、ということを表しています。
グラフを見ていただけると分かる通り、取りうる値の範囲が時間スケールで変化しています。このことから、未来に対して、同じ分布を期待できないことが分かります。このように、株価を標準化・正規化したとしても、その値は未来に対しても適用できる保証がないという事が分かりました。

これまでに挙げたグラフは、プライム市場におけるターゲットと株価ということで、若干理解し難いと思います。
そこで、個別銘柄の終値ではどのような分布の変化があるのか確認したいと思います。以下は、日本取引所グループにおける株価の推移をプロットしたものです。
以下のグラフからは、期間によって株価の分布が異なることがわかります。そして、2021年4月から2022年1月にかけて株価が上昇し、2022年4月にかけて株価が少し下落していることが分かります。これはプライム市場においてvalue(Z値)がプラスの方向へと作用するトレンドをもった銘柄であるということが分かります。

次に、終値と今回のターゲットをそれぞれプロットしました。終値(青)は年度が進むに連れて値が下降傾向にあることが分かります。このことから、非定常過程であることが分かります。一方、ターゲット(赤・緑)は、年度を通して、多少の上下は確認できますが、全体の傾向としては一定であり、弱定常過程となっていると考えられます。

最後に、ターゲットが単位根仮定(データの原系列は非定常であるが、差分をとると(弱)定常になるようなデータ)であるかどうかを調べるために、ADF検定を行いました。ADF検定では帰無仮説が「単位根仮定である」というもとで検定を行っています。
df = df_price[df_price['Local Code'] == 8697]['EndOfDayQuote Close'].copy()
print('Results of Dickey-Fuller Examination:')
dftest = adfuller(df)
dfoutput = pd.Series(dftest[0:4], index=['Test Statistic','p-value','#Lags Used','Number of Observations Used'])
for key,value in dftest[4].items():
dfoutput['Critical Value (%s)'%key] = value
print(dfoutput)
<実行結果>
Results of Dickey-Fuller Examination:
Test Statistic -1.262573
p-value 0.646117
#Lags Used 0.000000
Number of Observations Used 468.000000
Critical Value (1%) -3.444400
Critical Value (5%) -2.867736
Critical Value (10%) -2.570070
dtype: float64
終値の場合、ADF検定において帰無仮説が棄却されず、単位根仮定があると結論づけられます。一方、上記と同様にターゲットを検定した結果、p値が0.000004となりました。つまり、ターゲットは帰無仮説が棄却され、(弱)定常性があると言えそうです。(実際のところ、これでもまだ定常性があると結論づけることは難しく、コロナのような外部影響が、マーケットの変化率の分布を歪ませる期間が存在することがあります。コンペのディスカッションでは、さらに定常性を向上させるために、正規化などの他の手法などが紹介されていました。また、そのような外部要因にも対応するためにも、J-Quantsにて無料で提供される2年分のデータでは分析に限界がありそうです(最低5年位は必要になりそう?)。
ターゲットの特徴について理解できたところで、いよいよ分析を行っていきたいと思います。大まかな流れは以下の通りです。
- データの取得・整形
- 特徴量作成
- 予測
なお、分析を一貫し、定常性を意識したデータ作成を行うことがポイントとなりそうです。
また、ターゲットに関しての説明が多くなってしまったので、これから先は手短に紹介していきます、、、
データの取得と整形
データの取得・整形では、J-Quants APIから取得できる、ファンダメンタル情報、株価情報、銘柄一覧のそれぞれのデータを整形し、株式分析チュートリアルに適用できるように、変数名や型を変換していきます。また、このときに目的変数も、先程の計算式から作成します。
ここで一点注意しなければならないのは、累積調整係数についてです!
累積調整係数とは、企業が株式分割や株式併合を行った際に、その影響を反映させるために用いられる数字のことを言います。そして、株式の価格と流通株式数が同時に変わるので、それに対する調整を行います。
たとえば、企業Aが2023年の7月1日に株式分割を行い、1株あたりの価格が半分になったとします。この時点で、累積調整係数は2になります。この指標は、分割前の株価(調整前株価)を求めるために使われます。つまり、分割後の株価(調整済株価)に累積調整係数を掛ければ、分割前の株価が得られます。同様に、出来高についても調整が必要です。分割後、取引された株式数は2倍になるので、その影響を除去するために出来高を累積調整係数で割ります。これにより、分割前の出来高(調整前出来高)が求まります。
ただし、この累積調整係数は将来の情報を含んでいるため、その日付時点で知り得ない情報が含まれていることに注意が必要です。たとえば、2023年6月30日時点では、7月1日の株式分割はまだ発生していないので、累積調整係数は1であるべきです。しかし、分割が発生した後、6月30日のデータを見返すと、累積調整係数は2となっています。これは、その日付時点では知り得ない未来の情報が含まれているということを示しています。
このような未来の情報をモデルに入力することは、情報のリーク(情報漏洩)となり、モデルの正確性に悪影響を与える可能性があるようです。そのため、モデルが適切に学習し、実世界の状況を適切に予測するためには、その日付時点で得られる情報のみを使用することが重要となります!
なお、更にリークについての詳しい説明に関しては、ファンダメンタルズ分析チャレンジのフォーラムにて紹介されていますので、大変参考になるかと思います!
特徴量作成
続いて、特徴量の作成を行います。
機械学習の手法にはモデルにできるだけ生に近いデータを与えてその関係性を見つける手法と、ドメイン知識や専門性を活かして、特徴量を設計する手法があるそうです。今回は後者の方法で行いましたが、この特徴量の作成が予測の確度にも大きく寄与しそうです。そして、特徴量の作成には、ドメイン知識が要求されるため、金融に精通している方ほど、金融データに即した効果的なモデルが構築できそうです。また、繰り返しにはなりますが、特徴量作成においても定常性を意識した設計が重要視されてきます。
筆者のドメイン知識はまだ未熟であるので、コンペ上位の方のモデル(UKIさんのモデル)を参考に、どのような特徴量を作成していたのか、その特性に迫りながら確認していきたいと思います。

上記の表は、全特徴量とその計算式について記述されたものになります。
価格データでは四本値(高値、安値、始値、終値)を基にして、データの変化のパターンを多角的に表す試みが行われていることが分かります。一般的に、レンジは高値から安値を引くことで計算され、この結果は原則として単位を持つ値になります。しかし、この形式の値を直接データ分析モデルに適用しようとすると、うまく機能しません。というのも、期間による価格スケールに違いがあるといった非定常過程にあることに加え、異なる銘柄での比較ができないからです。そこで、レンジを「レンジ/前日の終値」といった形で表現しています。これは、終値を1という基準にしたときの、相対的な価格変動の幅を表しています。そして、"レンジ"という情報をデータ分析モデルに適切に反映させることができます。
また、財務データでは企業の「収益性」、「生産性」、「安全性」、「成長性」などの性質を多角的に表す試みが行われていることが分かります。財務データでは、rawとratio、diffという3区分で特徴量が生成されています。rawとratioは原系列と呼ばれており、前期と当期における季節的な変動を取り除く前のものを指します。つまり、原系列データのままでは、経済的な変動を評価しづらいということになります。そこで、diffという特徴量により、差分を取ることによって季節変動を修正しています。
特徴量の特性
続いて、各特徴量がターゲットに対してどの用にワークするのかを、グラフ化して確認していきたいと思います。
その前に、ボラティリティと期待値、試行回数のシミュレーションから、株価がどのように変動していくのかについて見ていきましょう!
以下の図は、トレード数を200とし、リターンの母集団の期待値を0と0.2、リターンの母集団の標準偏差を1と2にしたときのシミュレーション結果です。
はじめに、ボラティリティから見ていきます。ボラティリティの意味そのものではありますが、1から2へと変化すると価格変動の度合いが大きくなっています。そして、ボラティリティが高くなるほど、上振れと、下振れの程度が激しくなっています。つまり、ボラティリティが大きくなると、高値は大きくなり(正の相関)、安値は小さくなる(負の相関)事が分かります。
次に、リターンの期待値について見ていきます。期待値が0のときから0.2へと変わると、全体的なシミュレーションの結果が上振れしています。つまり、期待値が0ではない、トレンドを持つようなときは、トレンドが発生していると高値は大きくなり(正の相関)、安値も大きくなる(正の相関)事が分かります。

このように、シミュレーション結果から、ボラティリティ・トレンドと高値・安値の関係性を見てきました。それでは、今回作成した特徴量が、これら2つのボラティリティ予測、方向予測に対する情報を持っているのかを調べたいと思います。
以下の図は、高値側と安値側の2つのターゲットと、各特徴量との順位相関をプロットしたものになります。詳しくはUKIさんの説明資料を参照してください。
このグラフは、横軸にボラティリティ予測の評価指標、縦軸に方向予測の評価指標をプロットしたものになります。また、特徴量を価格系と財務系で色分けし、表示させました。このグラフからは、ボラティリティ予測には価格系の特徴量が、方向予測には財務系の特徴量が有用であることが分かります。

このことから、決算短信発表後の20営業日の間における当該企業の株価の最高値及び最安値を予測するタスクにおいて、価格データはボラ予測、財務データは方向予測の情報を持っていることが分かります。
予測
さて、いよいよモデルを作成して決算の良し悪しを予測していきたいと思います!
モデルはXGBRegressorを使用し、J-Quants APIの無料版で使用できる2年分のデータのうち、2021/03/08 ~ 2022/05/18を訓練データとし、2022/05/18 ~ 2023/02/03をテストデータとしました。
テストデータにおける予測の評価として、直近400個の高値における予測と正解ラベルから順位相関を計算したものをプロットしたものが以下となります。
この図から、実際に発生した高値のランキングとモデルが予測した高値のランキングが平均して0.42ほどの順位相関を記録していることが分かりました。つまり、決算発表後の高値・安値の順位相関はかなりの確度で予測可能であることが分かりました。tomo@Alpacaさんによる解説記事では、より詳細で分かりやすい説明が載っていますので、是非こちらの記事を参考にしてください。
latest_n: 400
label_high_20
count 178.000000
mean 0.426816
std 0.073452
min 0.205684
25% 0.376551
50% 0.410279
75% 0.471666
max 0.575425
dtype: float64
おわりに
今回は、決算の良し悪しを予測するモデルを構築してきました。そして、この決算というカタリストが存在するなかでは、価格データはボラティリティ予測に貢献し、財務データは方向予測、つまりトレンドを予測することに貢献することが分かりました。
また、株式市場分析を行う際、データを適切に処理し、特徴量を作成することは非常に難しい作業であることを実感しました。しかし、理論に従って適切な処理を施すことで、確度が上がることを実感し、株式市場のデータをさらに分析していきたいと感じました!