Alteryxとは
プログラミングができなくてもETLを簡単・高速に行うことができるソフトウェアです。詳細はこちら
いろいろなアイコンをつなげてデータ処理をしていくので、後からたどるのが比較的容易です。
そんなAlteryxの裏側ではPythonが走っていると過去のイベントで聞きました。(随時開発していてPythonだけでもないらしいです)
つまりはPython書けなくてもPythonで行うような処理が簡単に組める、ということです。ありがたや。
なぜPythonだけにしないのか
Pythonを勉強したらいいことは重々承知なんですが、やっぱり難しいんです。
Alteryxみたいにローコードやノーコードな手段でデータ処理に足を踏み入れてしまうとPythonの壁ってより高く感じます…
できるだけAlteryxの既存のツールで済ませたい!
AlteryxのPythonツール
Developer群に入っています。(早速お気に入りに追加してみました)
右クリックをしてサンプルを開いてフローを実行してみると使い方の詳細がわかります。
特徴としては以下の通りです。
- ツールの中でjupyter notebookに記述する感じ(詳細を後述)
- インプットをpandasのDataFrameに変換して扱う
- アウトプットも現状pandasのDataFrameにしか対応していない
フローを作る
夏目漱石の「吾輩は猫である」の頻出動詞を多い順に並べてみます。
最初にフローの全容をお見せするとこんな感じです。

Pythonの処理が苦手なので、janomeを使うところ以外はすべて既存のツールで処理しています。
ざっくり以下の手順で進めました。
- 青空文庫からダウンロードしたテキストファイルを読み込む
- 最初と最後の余分な行を除く
- NULLや字下げの指示を除く
- janomeをPythonツールで実行して分かち書きした状態を渡す
- 1行内に複数単語と個数が含まれるので分割する
- 単語ごとの集計を行う
- 降順に並べる
Pythonツールの中身
Run Alteryx.help() for info about useful functions.
i.e., Alteryx.read("#1"), Alteryx.write(df,1), Alteryx.getWorkflowConstant("Engine.WorkflowDirectory")
# List all non-standard packages to be imported by your
# script here (only missing packages will be installed)
from ayx import Package
#Package.installPackages(['pandas','numpy'])
from ayx import Alteryx
import pandas as pd
import numpy as np
df = Alteryx.read('#1')
# SUCCESS: reading input data "#1"
import collections
Alteryx.installPackages("janome")
# Requirement already satisfied: janome in c:\program files\alteryx\bin\miniconda3\envs\designerbasetools_venv\lib\site-packages (0.4.1)
from janome.tokenizer import Tokenizer
t = Tokenizer()
def wakati(x):
return collections.Counter(token.base_form for token in t.tokenize(x)
if token.part_of_speech.startswith('動詞,自立'))
wakati_result = df.Field_1.apply(wakati)
df_wakati = pd.DataFrame(wakati_result)
Alteryx.write(df_wakati,1)
# SUCCESS: writing outgoing connection data 1
アウトプット
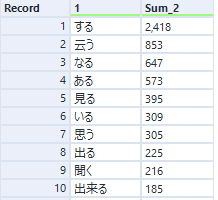
動詞を抜き出して並べることができました。云うが入っているあたりに時代を感じます。
今回は青空文庫のテキストを使用しましたが、顧客アンケートからキーワードを抜き出して分析する、みたいな使い方もできそうな予感がしています。
Pythonツールの使い方のコツ
インターフェースがちょっと使いにくい
jupyter notebook風なので中でRunできるのかと思いきや…できない!
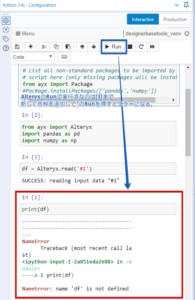
dfってすぐ上で定義してるのに…Alteryxのフロー全体を実行しなおさないとダメでした。
都度都度importなどをしているので時間がかかる
jupyter notebookと違って、一部だけ実行することができないので時間がかかります。
今回の例だと23~30秒ほど実行にかかりました。
Pythonツールの中身をちょっと変更…もできないのでその度に実行しなおす必要があります。
Alteryxの他のツールのサクサク動く感じに慣れてしまっていたのでちょっと長いな、と思ってしまいました。
やたらエラーマークが出る
最初にPythonツールを置いたとき、インプットのキャッシュのためと、スクリプトの実行のために2回フローを実行する必要があります。
その後もフローのどこか直す(アイコンの位置調整を含む)度にエラーマークが出ますが、実行すると消えます(地味に鬱陶しい)

まとめ
janomeでの処理を先にjupyter notebookで試してからよし、yxmdのフロー組もうと意気込んだのですが、
DataFrameの扱いが上手くいかなくて普段からPythonを書いている同僚にPythonツールの中身に関して助けてもらいました。
ちょっと助けてもらえたら後はAlteryxで自分でできる!という方にはPythonツールを使うとかなりできることの幅が広がります。
いきなり全部Pythonで書く、というのはハードルが高いと感じている方(私を含め)にはPythonやプログラミングコードの勉強の入り口になるかもしれません。
Pythonで処理ができるけどそれほどコードが読めない担当者と共有する、という観点でもAlteryxは可読性が高いのでおすすめです。
ぜひお試しあれ!