
文章を分類するウェブアプリを作ろう
ラーメン食べてますか。
ラーメンに関するツイートについて札幌と福岡のどちらでツイートされたか判別するウェブアプリをデプロイしたので、「モデル編」「ウェブアプリ編」に分けて記録を残そうと思います。全体の流れを重視したので、細かい中身についてはリンク先も見てみてください。
自然言語処理もウェブアプリも勉強始めて一年にも満たない人間なので躓くところがたくさんありましたが、そういう部分も書いておこうと思います。
ウェブアプリ編:文章を分類するウェブアプリをデプロイしよう(ウェブアプリ編)
完成品はこちら
ちなみにdeepblueのHPにDemo appページができました。まだ各アプリのページについてはヘッダーのリンクがつながっていなかったりしますが、アプリは動くのでよかったら遊んでみてくださいね。
利用した技術とサービス
- バックエンドの言語:python
- ディープラーニングライブラリ:pytorch, torchtext
- 自然言語処理モデル:双方向LSTM
- ウェブフレームワーク:FastAPI
- デプロイ:Google app engine, docker, Git
環境:Google colaboratory
最初はいつもの通りGoogle colaboratoryを使っていたのですが、バージョン管理するために改めてローカルで環境を作らなければいけなかったので、今回は最初からローカルでやったほうがよかったかもしれないです。
モデル全体は下記のコードを参考にさせていただきました。
Pytorch text classification : Torchtext + LSTM
ライブラリ
from google.colab import drive
drive.mount('/content/drive')
rootpath = "XXX"
! pip install japanize_matplotlib
! pip install janome
! pip install dill
import matplotlib.pyplot as plt
import japanize_matplotlib
import pandas as pd
import re
from janome.tokenizer import Tokenizer
import numpy as np
import dill
import time
from sklearn.model_selection import train_test_split
import torch
from torchtext import data
import torch.nn as nn
from torchtext.vocab import Vectors
データの準備
今回はツイッターからのデータ取得は扱いませんが、「ラーメン」を含むツイートを札幌と福岡近辺からそれぞれ2週間分取得して、絵文字などを取り除き、pandas形式にしてあります。
前処理にはTweetlを使いました。
特定の場所のツイートを取得するのは前に書いた記事を参考にしてください。targetが0札幌近辺のツイート、1が福岡近辺のツイートです。
ちなみに、事前にnlplotを使って探索的データ分析をしていて、勝算があるかどうか簡単に確認しています。札幌のツイートには「味噌」、福岡は「豚骨」が頻出するので、そういうところをちゃんと組み込めれば性能の良いモデルになりそうです。
df_tw = pd.read_pickle(rootpath + '札幌福岡ラーメン_clean_1w_tweetdata_blog.pkl')
df_tw.head()
| text | target | |
|---|---|---|
| 0 | ラーメンが食べたくなって「あっ」と思い出して札駅北口に新しく出来た店へduck ramen eijiの新店らしいが正しい店名がわからない(笑)鴨だしjourney?しかも0円️「鴨だしジャーニー中華そば」スープ…う、うんまぁい️煮玉子は半熟、チャーシューはしっとりこれで0円は驚き️ | 0 |
| 1 | ノルベサの前にあるお店のラーメンでした。マジで美味かったす今回セットだったけど醤油ラーメン0杯0円しかしないしめっちゃ良くね? | 0 |
| 2 | 今月0日(金)0日迄旭川フィールにて直伝屋が出店致します!!旭川フィール限定で【red塩ラーメン】提供します。塩ラーメン自体も旭川フィール用に”あおり”ます是非この機会に旭川フィールにお越しください。#直伝屋#旭川フィール#旭川#ラーメン | 0 |
| 3 | ラーメンのイベントは延期の延期になるし、こども達とは会えないし……コロナめ | 0 |
| 4 | 0人お出かけでお茶して。帰りにお昼食べてきた。あんかけラーメン最高に美味しかった | 0 |
データセット全体を学習用(データの60%)、検証(データの20%)、テスト用のデータ(データの20%)のデータセットに分割します。
今回のケースでは分割しただけだと学習が上手く進まなかったので、どのデータセットもサンプルサイズがバッチサイズの倍数になるように調整しました。バッチサイズは128にすることにしたので、最初にデータセット全体を1280で割りきれる数にしてあります。
df_tw_1 = df_tw.query("target=='1'")
df_tw_0 = df_tw.query("target=='0'").sample(n=len(df_tw)//1280*1280 - len(df_tw_1), random_state=0)
df_tw2 = pd.concat([df_tw_1, df_tw_0], join="outer")
train_df, valid_df = train_test_split(df_tw2, stratify=df_tw2["target"], train_size=0.6)
valid_df, test_df = train_test_split(valid_df, stratify=valid_df["target"], test_size=0.5)
インストールが簡単なので、分かち書きはjanomeを使いました。
def tokenizer(text):
t = Tokenizer()
return [tok for tok in t.tokenize(text, wakati=True)]
ここからtorchtextの出番です。DatasetとDataLoader(の一種であるBucketIterator)という2種のイテレータを作ります。イテレータなので中はfor関数で中身を取り出せます。
イテレータが2つある意味がよくわからず混乱しましたが、Datasetは単語をIDに変換するためのイテレータ、DataLoaderは変換したIDをモデルに送り込む際に順番を変えたり、バッチにまとめたりするためのイテレータと理解しています。
このブログをよく読ませていただきました。
pandasのDataFrameをデータソースに使うためにクラスを作ります(参考Github)。今思うと、元のデータがCSV、TSV、jsonのいずれかならtorchtextにもともとあるクラス(TabularDataset)が使えるので、最初からそれを意識したほうがよかったかも。
今回はtest_dfにも正解ラベルがあるので、is_testは全部Falseにしてあります。
class DataFrameDataset(data.Dataset):
def __init__(self, df, fields, is_test=False, **kwargs):
examples = []
for i, row in df.iterrows():
label = row.target if not is_test else None
text = row.text
examples.append(data.Example.fromlist([text, label], fields))
super().__init__(examples, fields, **kwargs)
@staticmethod
def sort_key(ex):
return len(ex.text)
@classmethod
def splits(cls, fields, train_df=None, val_df=None, test_df=None, **kwargs):
train_data, val_data, test_data = (None, None, None)
data_field = fields
if train_df is not None:
train_data = cls(train_df.copy(), data_field, **kwargs)
if val_df is not None:
val_data = cls(val_df.copy(), data_field, **kwargs)
if test_df is not None:
test_data = cls(test_df.copy(), data_field, **kwargs)
return tuple(d for d in (train_data, val_data, test_data) if d is not None)
TEXT = data.Field(tokenize = tokenizer, include_lengths = True)
LABEL = data.LabelField(sequential=False, use_vocab=False)
fields = [('text',TEXT), ('label',LABEL)]
train_ds, val_ds, test_ds = DataFrameDataset.splits(fields, train_df=train_df, val_df=valid_df, test_df=test_df)
埋め込み表現は学習済みのfastTextをダウンロードして使うことにしました(参考Qiita)。このfastTextはMeCabで分かち書きしているのでモデルの分かち書きもMaCabにした方がいいと思うのですが、今後の課題ということにします。
あとはtrain_dsとfastTextを使ってVocabオブジェクトを作ります。
path = rootpath + "fasttext_model.vec"
vectors = Vectors(name=path)
MAX_VOCAB_SIZE = 15000
TEXT.build_vocab(train_ds, vectors=vectors,
max_size = MAX_VOCAB_SIZE,
unk_init = torch.Tensor.zero_)
LABEL.build_vocab(train_ds)
ところで、最終的にはこのコード全体をウェプアプリとして使うことはしません。fastTextが重すぎるからです(Gitにpushしようとしてエラーが出たとき初めて気付きました)。 これは当然で、今回IDに変換して利用する単語は15000語しかないのに、fastTextはもっとたくさんの単語について埋め込み表現を持っているからです。
そこでLABELとTEXTを保存して、アプリを使う上ではこれをロードすることにしました。
pickleで書き出ししようとしたのですが、中に無名関数が入っていると上手く行かないようなので、dillを利用しました。
with open(rootpath + "LABEL.dill", 'wb') as f:
dill.dump(LABEL, f)
with open(rootpath + "TEXT.dill", 'wb') as f:
dill.dump(TEXT, f)
# ロードはあとでやります
バッチサイズとデバイス(CPUかGPUか)を指定して、DataLoaderを作ります。BucketIteratorはDataLoaderの一種で、バッチ化する際に学習がしやすいよう、勝手に順番に並べ替えてくれます。
BATCH_SIZE = 128
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator = data.BucketIterator.splits(
(train_ds, val_ds),
batch_size = BATCH_SIZE,
sort_within_batch = True,
device = device)
LSTMモデルとEarlyStopのクラスを作ります。詳細は前述したkaggleのコードを参照してください。
# LSTM
class LSTM_net(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers,
bidirectional, dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx = pad_idx)
self.rnn = nn.LSTM(embedding_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=bidirectional,
dropout=dropout)
self.fc1 = nn.Linear(hidden_dim * 2, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, 1)
self.dropout = nn.Dropout(dropout)
def forward(self, text, text_lengths):
embedded = self.embedding(text)
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths.cpu())
packed_output, (hidden, cell) = self.rnn(packed_embedded)
hidden = self.dropout(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim = 1))
output = self.fc1(hidden)
output = self.dropout(self.fc2(output))
return output
def binary_accuracy(preds, y):
rounded_preds = torch.round(torch.sigmoid(preds))
correct = (rounded_preds == y).float() #convert into float for division
acc = correct.sum() / len(correct)
return acc
def train(model, iterator):
epoch_loss = 0
epoch_acc = 0
model.train()
for batch in iterator:
text, text_lengths = batch.text
label = batch.label.float()
optimizer.zero_grad()
predictions = model(text, text_lengths).squeeze(1)
loss = criterion(predictions, label)
acc = binary_accuracy(predictions, label)
loss.backward()zs
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
def evaluate(model, iterator):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in iterator:
text, text_lengths = batch.text
label = batch.label.float()
predictions = model(text, text_lengths).squeeze(1)
loss = criterion(predictions, label)
acc = binary_accuracy(predictions, label)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
class EarlyStopping:
def __init__(self, patience=5, verbose=True):
self._loss = float('inf')
self.patience = patience
self.verbose = verbose
def __call__(self, loss):
if self._loss < loss:
self._step += 1
if self._step > self.patience:
if self.verbose:
print('early stopping')
return True
else:
self._step = 0
self._loss = loss
return False
学習
ハイパーパラメーターを決めて、fastTextによるベクトル表現を埋め込み層に入れたら学習させます。
num_epochs = 100
learning_rate = 0.0005
INPUT_DIM = len(TEXT.vocab) # 文章全体の単語数
EMBEDDING_DIM = 300 # 300次元の埋め込み
HIDDEN_DIM = 256 # 隠れ層の次元数
OUTPUT_DIM = 1 # 01データだから
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.5
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token] # padding
model = LSTM_net(INPUT_DIM,
EMBEDDING_DIM,
HIDDEN_DIM,
OUTPUT_DIM,
N_LAYERS,
BIDIRECTIONAL,
DROPOUT,
PAD_IDX)
pretrained_embeddings = TEXT.vocab.vectors
model.embedding.weight.data.copy_(pretrained_embeddings)
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)
model.to(device)
criterion = nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
t_start = time.time()
loss = []
acc = []
val_acc = []
val_loss = []
es = EarlyStopping()
for epoch in range(num_epochs):
train_loss, train_acc = train(model, train_iterator)
valid_loss, valid_acc = evaluate(model, valid_iterator)
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f'\tVal. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}%')
loss.append(train_loss)
val_loss.append(valid_loss)
acc.append(train_acc)
val_acc.append(valid_acc)
if es(valid_loss):
break
print(f'time:{time.time()-t_start:.3f}')
print(val_acc[-1])
print(epoch)
print(f'time:{time.time()-t_start:.3f}')
学習が終わったのでモデルの重みを保存します。
torch.save(model.state_dict(), rootpath + "ramen_model.pt")
結果をプロットしてみますと、accurancyはは0.7くらいでした。うーん……。
plt.xlabel("runs")
plt.ylabel("normalised measure of loss/accuracy")
x_len=list(range(len(acc)))
plt.axis([0, max(x_len), 0, 1])
plt.title('result of LSTM')
loss=np.asarray(loss)/max(loss)
val_loss=np.asarray(val_loss)/max(val_loss)
plt.plot(x_len, loss, 'r.',label="loss")
plt.plot(x_len, acc, 'b.', label="accuracy")
plt.plot(x_len, val_loss, 'y.', label="val_loss")
plt.plot(x_len, val_acc, 'g.', label="val_accuracy")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.2)
plt.show
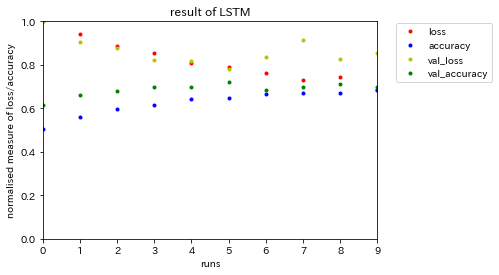
どんなツイートが誤同定されているのか、テスト用データで確認してみます。テスト用のデータセットは既に作られているので、あとはBucketIteratorを作るだけです。
test_iterator = data.BucketIterator(
dataset = test_ds,
batch_size = BATCH_SIZE,
sort_within_batch = True,
device = device)
BucketIteratorからどうやって元のツイート文を復元すればいいかわからずちょっと苦労しましたが、idをitos(identifiers to stringsの略です。だから逆はstoi。)で変換することにしました。未知語が未知語のまま出てきてしまうという問題があるのですが、まぁそれこそモデルが読んでるものなので、これでいいことにします。
model.eval()
tf_tensor = torch.tensor([99], device=device) # 答え入れる用のテンソル(あとで1個分削除する)
test_text = []
test_label_ans = np.array(99)
with torch.no_grad():
for batch in test_iterator:
text, text_lengths = batch.text
predictions = model(text, text_lengths).squeeze(1)
rounded_preds = torch.round(torch.sigmoid(predictions))
tf_tensor = torch.cat((tf_tensor, rounded_preds), 0)
tweet = [[TEXT.vocab.itos[text[i, j]] for i in range(max(text_lengths))] for j in range(len(text[0]))]
test_text.append(tweet)
test_label_ans = np.hstack((test_label_ans, batch.label))
test_text = ["".join(i) for i in sum(test_text, [])]
len(test_text)
test_label_ans = list(test_label_ans[1:])
tf_tensor = tf_tensor[1:]
tf_tensor.size()
test_label_pred = list(map(int, list(tf_tensor.to('cpu').numpy())))
test_pred_df = pd.DataFrame({"label_pred" : test_label_pred,
"label_ans" : test_label_ans,
"text":test_text})
test_pred_df.query("label_pred != label_ans").head()
| label_pred | label_ans | text | |
|---|---|---|---|
| 1 | 0 | 1 | もう<unk>やったけど、取ってきましたwラーメンで暖をとってます<pad> |
| 3 | 0 | 1 | 寿司屋のラーメンかあ️完全に頭になかったですそれはアリですね<pad> |
| 7 | 0 | 1 | カップの辛ラーメンにウインナーぶっ込んでチーズいれたらバカうまい️今日の昼ごはん<pad> |
| 11 | 0 | 1 | 今日はどこのラーメン食べに行こうか#ゆり<unk>周南#ゆり<unk>下松<pad> |
| 12 | 0 | 1 | 目が<unk>てるんかな️ラーメンが0杯に見える( °ω°)<pad> |
なるほど。元のツイートの中には「札幌らしさ」も「福岡らしさ」もないツイートがたくさん含まれてるんですね。ちょっと解決しがたいのでこれでいいことにします。
本来ならここからOptunaを使ってハイパーパラメーターを選択したり、モデル自体を選び直してモデルを改善していくと思いますが、今回はこのまま進みます。
ウェブアプリにする準備をしよう
ここまでjupyter notebook形式(.inpyb)で書いていましたが、別のpythonファイル(.py)を準備してウェブアプリにする準備をしていきます。
作ったTEXTとLABELをmake_field関数で読み込んで、その後の流れは上記のコードとおおよそ共通しています。
import pandas as pd
from janome.tokenizer import Tokenizer
import dill
import torch
from torchtext import data
import torch.nn as nn
from torchtext.vocab import Vectors
# LSTM
class LSTM_net(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers,
bidirectional, dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx = pad_idx)
self.rnn = nn.LSTM(embedding_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=bidirectional,
dropout=dropout)
self.fc1 = nn.Linear(hidden_dim * 2, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, 1)
self.dropout = nn.Dropout(dropout)
def forward(self, text, text_lengths):
embedded = self.embedding(text)
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths.cpu())
packed_output, (hidden, cell) = self.rnn(packed_embedded)
hidden = self.dropout(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim = 1))
output = self.fc1(hidden)
output = self.dropout(self.fc2(output))
return output
def model_load(fields):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
TEXT = fields[0][1]
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 300
HIDDEN_DIM = 256
OUTPUT_DIM = 1
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.5
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = LSTM_net(INPUT_DIM,
EMBEDDING_DIM,
HIDDEN_DIM,
OUTPUT_DIM,
N_LAYERS,
BIDIRECTIONAL,
DROPOUT,
PAD_IDX)
model.to(device)
model_weight = torch.load(rootpath + "ramen_model.pt")
model.load_state_dict(model_weight)
return model
def tokenizer(text):
t = Tokenizer()
return [tok for tok in t.tokenize(text, wakati=True)]
def make_field():
TEXT = dill.load(open(rootpath + "TEXT.dill",'rb'))
TEXT.tokenize = tokenizer
LABEL = dill.load(open(rootpath + "LABEL.dill",'rb'))
fields = [('text',TEXT), ('label',LABEL)]
return fields
def text_to_ds(text, fields):
example = [data.Example.fromlist([text, None], fields)]
test_ds = data.Dataset(example, fields)
return test_ds
def ds_to_iterator(test_ds):
test_iterator = data.BucketIterator(
dataset = test_ds,
batch_size = 1,
sort_within_batch = True,
)
return test_iterator
def lstm_model(text):
fields = make_field()
TEXT = fields[0][1]
test_ds = text_to_ds(text, fields)
test_iterator = ds_to_iterator(test_ds)
model = model_load(fields)
model.eval()
ans_tensor = torch.tensor([99])
with torch.no_grad():
for batch in test_iterator:
text, text_lengths = batch.text
predictions = model(text, text_lengths).squeeze(1)
confidence = torch.sigmoid(predictions)
rounded_preds = torch.round(confidence)
ans_tensor = torch.cat((ans_tensor, rounded_preds), 0)
tweet = [[TEXT.vocab.itos[text[i, j]] for i in range(max(text_lengths))] for j in range(len(text[0]))]
pred_text = "".join(tweet[0])
pred_label = "札幌" if ans_tensor[1:].item()==0 else "福岡"
# 1個分削除してラベルを場所に変更
pred_conf = "あんまり自信ない" if 0.3 < confidence < 0.7 else "結構自信ある"
return pred_text, pred_label, pred_conf
やっとpython側の準備が完了です。次回はこれをウェブアプリにしていきます。
Header photo by Hari Panicker on Unsplash

