GCP使ってますか。私はまだあまり使ってません。
使っていないのですが、Cloud Vision APIをちょっとだけ触る機会があったので、初心者なりにそこに至るまでの手順をまとめておきます。
※ 2020年9月時点での情報です
GCPのサービスについて
料金
Google Cloud Platformに登録するとCloud Vision APIを含めて様々なサービスが使える三ヶ月300ドルの無料トライアルがあります。有料会員になったあとも1000リクエストまでは無料で使えます。無料トライアルにもこの枠があるので、今回やる物体検出では300ドル分のクレジットは減りません。1000リクエスト以降は機能によって料金が違いますが、簡単な物体検出は1000リクエスト1.5ドル程度です(詳細)。お手軽ですね。
ウェブ上のデモ
画像1枚なら会員登録しなくてもウェブ上でVision APIを試すことができます。
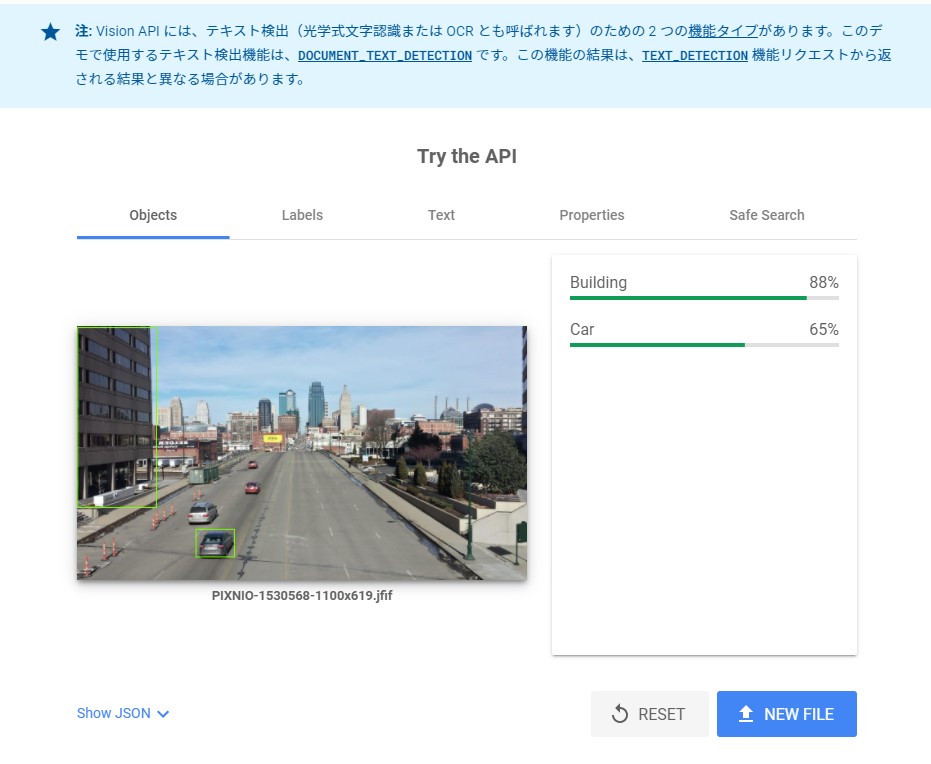
写真提供 PIXNIO
物体検出してみよう
GCPの登録
- Google Cloudに登録する
クレジットカード登録が必要ですが、勝手に課金されたりはしないので安心してください。
自動で一個目のプロジェクトが作成されます。
- プロジェクトでGoogle Vision APIを有効にする

- サイドバー>APIとサービス>認証情報
「+認証情報を作成」から「サービスアカウント」を選び認証情報を作成します。
サービスアカウント名:なんでもいい
サービスアカウントID:勝手に作成される
あとは空欄で可。

- 鍵を保存
認証情報のページに戻り、作ったサービスアカウントをクリックして詳細を表示します。
鍵を追加>新しい鍵の作成>キーのタイプ「JSON」を選択して保存します。
この鍵があれば誰でもGCP上のデータにアクセスできてしまうので、取り扱いには注意。


Vision APIの利用
公式リファレンスが結構丁寧です(ただしgoogle-cloud-visionパッケージにアップデートがあった関係で執筆時点では一部に誤りがあります。参考文献参照)。
ここからpythonで作業します。環境はJupyter notebookです。違う環境の場合OpenCV周りに調整が必要かもしれません。OpenCVは作業ディレクトリ内に日本語が入るとエラーになるので、含めないように注意しましょう(ここで3時間つまった)。
!pip install google-cloud==0.34.0
!pip install google-cloud-vision==2.0.0
import os
import io
import cv2
from matplotlib import pyplot as plt
from google.cloud import vision
# さっきの鍵JSONファイルのパスを渡す
credential_path = r"XXX"
# サービスアカウントキーへのパスを通す
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = credential_path
# 対象となる画像のファイルパス
file_path = r"YYY"
# 画像をvision APIで読み込む
with io.open(file_path, "rb") as image_file:
content = image_file.read()
image = vision.Image(content=content)
# visionクライアントの初期化
client = vision.ImageAnnotatorClient()
# Vision APIが動く
objects = client.object_localization(image=image).localized_object_annotations
結果のオブジェクトはバウンディングボックスごとに、Vision APIが定めたクラスID、クラスの名前、信頼度、標準化された座標データが「左上」「右上」「右下」「左下」の順に入っています。
print(objects)
# [mid: "/m/0cgh4"
# name: "Building"
# score: 0.8800451159477234
# bounding_poly {
# normalized_vertices {
# x: 0.0016767190536484122
# y: 0.006287668365985155
# }
# normalized_vertices {
# x: 0.17645347118377686
# y: 0.006287668365985155
# }
# normalized_vertices {
# x: 0.17645347118377686
# y: 0.7170488834381104
# }
# normalized_vertices {
# x: 0.0016767190536484122
# y: 0.7170488834381104
# }
# }
# , mid: "/m/0k4j"
# name: "Car"
# score: 0.6495059132575989
# bounding_poly {
# normalized_vertices {
# x: 0.2646287977695465
# y: 0.8036816120147705
# }
# normalized_vertices {
# x: 0.3498062789440155
# y: 0.8036816120147705
# }
# normalized_vertices {
# x: 0.3498062789440155
# y: 0.9126953482627869
# }
# normalized_vertices {
# x: 0.2646287977695465
# y: 0.9126953482627869
# }
# }
# ]
OpenCVを使って検出結果を画像に上書きします。OpenCVのcv2.rectangleとcv2.putTextはint型(整数)しか受け取れないので座標の型を変換しましょう。
# 画像をOpenCVで読み込む
img = cv2.imread(file_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # BGR→RGBに変換
# OpenCVのデータから写真のサイズを取得。順番に注意。縦、横(、チャンネル数)の順に入力される。
fig = plt.figure(figsize=(11.46, 6.45), dpi=96)
img2 = img.copy()
h, w = img2.shape[0:2]
color = (255, 255, 0)
font = cv2.FONT_HERSHEY_DUPLEX
for obj in objects:
# バウンディングボックスの左上と右下の角の座標を取得して書き足す
box = [(v.x * w, v.y * h) for v in obj.bounding_poly.normalized_vertices]
cv2.rectangle(img2, tuple(map(int, box[0])), tuple(map(int, box[2])), color, 3)
# オブジェクトの名前を取得して書き足す
obname = obj.name
cv2.putText(img2, obname ,tuple(map(int, box[2])), font,
2, color)
plt.imshow(img2)
plt.show()

上記のような画像ができました。車がいくつか認識できていませんね。またクラスは「建物」「車」の2つだけのようです。
Vision APIは学習済みモデルなのですぐに結果がわかり、パラメーターの調整も必要ありません。一方でクラスを追加することができず、結果が望むものでなくてもハイパーパラメーターの調整(例えば最終的にボックスを出す閾値など→前のブログ記事)や再学習はできません。
AutoML Visionを使うと、独自に定義したラベルに従って画像を分類するよう、アノテーションを追加してモデルを訓練できます。ただし、これでもハイパーパラメーターの調整はできません。あと、AutoMLはちょっとお高い。
AutoML Visionで解決しない場合は自分でモデルを構築するのが最も自由度が高い方法です。
参考文献
Header photo on PIXNIO(一部改変)