MASライブラリ "mesa"を用いたQ学習の実装
はじめまして、インターンの中本です。
今回は、つくりながら学ぶ!深層強化学習 PyTorchによる実践プログラミング にあるQ学習を使った迷路課題をPythonのマルチエージェントシミュレーション(MAS)用ライブラリであるmesaを用い, google colaboratory上で実装してみました.
実装したノートブックはこちらに置いてありますので参考にしてみてください.
Contents
- 環境構築
- 準備
- 学習
- 可視化
- 結論と雑考
マルチエージェントシミュレーション
マルチエージェントシミュレーション(以下MAS)は各々が内部状態をもち、自律的に意思決定する”エージェント”を複数持つ環境を構成し、複雑な事象をモデル化しよう!というものです。特に交通や避難などの分野での応用が進んでいるようです。[1]
今回はMASを用いた強化学習(マルチエージェント強化学習、MARL)を行うための第一歩としてまずはエージェントが1体の環境でQ学習するモデルを作っていこうと思います。[2]
環境構築
mesaをインストールします.
pip install mesaCollecting mesa
[?25l Downloading https://files.pythonhosted.org/packages/20/e6/402b21f702498163df606e541f90dced4f9a570922f7faf22a193bd668f3/Mesa-0.8.6.tar.gz (627kB)
[K |████████████████████████████████| 634kB 2.8MB/s
[?25hRequirement already satisfied: click in /usr/local/lib/python3.6/dist-packages (from mesa) (7.0)
.......
.......
.......
Installing collected packages: binaryornot, whichcraft, poyo, arrow, jinja2-time, cookiecutter, mesa
Successfully installed arrow-0.15.5 binaryornot-0.4.4 cookiecutter-1.7.0 jinja2-time-0.2.0 mesa-0.8.6 poyo-0.5.0 whichcraft-0.6.1準備
エージェントの初期の方策を決定するパラメータtheta_0を作成します。
強化学習に関しては、つくりながら学ぶ!深層強化学習 PyTorchによる実践プログラミング を参照してください。
大雑把に言いますと、3 × 3の世界で、通れない壁があり、エージェントは基本的に上下左右の4方向に動けます。多くの場合には報酬が最大と予想される行動を選択して実際に行動しますが、ある確率以下(< ε)でランダムに行動を選択します。[3]
その得られる報酬の予測に用いるのが行動価値関数Qです。現在の状態と選択した行動(およびその行動の結果、至った状態)に対し、得られる予想報酬の値を返す関数です。今回は、Q学習というアルゴリズムを用いて行動価値関数Qを更新しています。
import numpy as np
# 行は状態0~7、列は移動方向で↓、→、↑、←を表す
theta_0 = np.array([[np.nan, 1, 1, np.nan], # s0
[np.nan, 1, np.nan, 1], # s1
[np.nan, np.nan, 1, 1], # s2
[1, 1, 1, np.nan], # s3
[np.nan, np.nan, 1, 1], # s4
[1, np.nan, np.nan, np.nan], # s5
[1, np.nan, np.nan, np.nan], # s6
[1, 1, np.nan, np.nan], # s7、※s8はゴールなので、方策はなし
])def simple_convert_into_pi_from_theta(theta):
'''単純に割合を計算する'''
[m, n] = theta.shape
pi = np.zeros((m, n))
for i in range(0, m):
pi[i, :] = theta[i, :] / np.nansum(theta[i, :])
pi = np.nan_to_num(pi)
return pi
# 初期の方策pi_0を求める
pi_0 = simple_convert_into_pi_from_theta(theta_0)direction = ["down", "right", "up", "left"]width = 3
height = 3
max_state = width * height - 1
agent_Q = np.random.rand(max_state, 4) * theta_0 # 初期の価値観数
eta = 0.1 # 学習率
gamma = 0.9 # 時間割引率
epsilon = 0.5 #ε-greedyagent_Qarray([[ nan, 0.05399243, 0.16585183, nan],
[ nan, 0.29218127, nan, 0.46750435],
[ nan, nan, 0.47989824, 0.77943044],
[0.48751429, 0.36541561, 0.59208522, nan],
[ nan, nan, 0.39585594, 0.66356116],
[0.14901966, nan, nan, nan],
[0.75532786, nan, nan, nan],
[0.18320129, 0.13332957, nan, nan]])迷路モデルとエージェント
迷路モデルとエージェントを定義していきます。
- 迷路モデルはエージェントが何回ゴールにたどり着いたかを表すepisodeと, エージェントがどれほどランダムに探索するかを表すepsilonを保持しています。[4]
- エージェントは状態を表すstate, 行動を表すaction, およびepsilonを保持しています。
- 報酬はゴール地点につくと +1もらえます。
全体の流れとしては、
エージェントがゴールしているなら消して、スタート地点に次のエージェントを配置→エージェントが次の状態を決定→行動価値関数更新→移動→現在のデータをDataCollectorであつめる
となっています。
from mesa.datacollection import DataCollector # agent, およびmodelの情報を集めてくれる
from mesa.space import MultiGrid # 一つのセルにエージェントが複数入ることのできるグリッド, 今回はSingleGridで問題はない
from mesa import Agent, Model
from mesa.time import RandomActivation # スケジューラ、エージェントを毎回ランダムな順番でアクティブにしてくれる
# 迷路モデル
class LabyrinthModel(Model):
def __init__(self, width, height, epsilon):
self.grid = MultiGrid(width, height, False) # 環境を定める, 最後の引数はトーラスにするかどうか
self.schedule = RandomActivation(self)
self.episode = 1
self.epsilon = epsilon
# RL_agnet出現
a = RL_agent(0, self, epsilon) # 下で定義されるエージェントクラス
self.schedule.add(a) # スケジューラに加える
self.grid.place_agent(a, (0, 0)) # グリッドに加える
self.datacollector = DataCollector(agent_reporters={"state": "state", "action": "action"})
#agentのstateとactionのデータを集める
# エージェントの出現および削除に関して
def remove_and_pop_agent(self):
last_cell = list(self.grid.coord_iter())[-1]
if last_cell[0] != set():
# ゴールについたら消える
for agent in list(last_cell[0]): # マルチエージェントにすることを意識したもの
self.grid.remove_agent(agent)
self.schedule.remove(agent)
a = RL_agent(self.episode, self, self.epsilon / (2 ** self.episode))
self.schedule.add(a)
self.grid.place_agent(a, (0, 0))
self.episode += 1
# modelのstepの進め方に関して
def step(self):
self.remove_and_pop_agent()
self.schedule.step()
self.datacollector.collect(self)
#Q学習エージェント
class RL_agent(Agent):
def __init__(self, unique_id, model, epsilon):
super().__init__(unique_id, model)
self.state = 0
self.action = 0
self.epsilon = epsilon #epusilonを時間とともに小さくしていくことを想定したもの
# 次の行動と状態の決定に関して
def get_s_and_a(self):
# ε-greedy
if np.random.rand() < self.epsilon:
# εの確率でランダムに動く
next_direction = np.random.choice(direction, p=pi_0[self.state, :])
else:
# Qの最大値の行動を採用する
next_direction = direction[np.nanargmax(agent_Q[self.state, :])]
# 行動をindexに
if next_direction == "down":
self.action = 0
self.state -= self.model.grid.width
elif next_direction == "right":
self.action = 1
self.state += 1
elif next_direction == "up":
self.action = 2
self.state += self.model.grid.width
elif next_direction == "left":
self.action = 3
self.state -= 1
# 価値関数の更新に関して
def Q_learning(self):
x, y = self.pos
now_state = y * self.model.grid.width + x
if self.state == 8: # ゴールした場合
# Q(s, a) ← Q(s, a) + eta * (reward - Q(s, a))
agent_Q[now_state, self.action] = agent_Q[now_state, self.action] + eta * (1 - agent_Q[now_state, self.action])
#報酬あり
else:
# Q(s, a) ← Q(s, a)
agent_Q[now_state, self.action] = agent_Q[now_state, self.action] + eta * (gamma * np.nanmax(agent_Q[self.state,: ]) - agent_Q[now_state, self.action]) #報酬なし
# 移動に関して
def move(self):
# stateを座標に変換
x = self.state % self.model.grid.width
y = self.state // self.model.grid.width
# 移動
self.model.grid.move_agent(self, (x, y))
#エージェントの行動順序に関して
def step(self):
self.get_s_and_a()
self.Q_learning()
self.move()学習
エージェントを学習させていきます。今回は100回ゴールにたどり着くまで学習させます。
model = LabyrinthModel(width=width, height=height, epsilon=epsilon)# 100回ゴールするまで学習させる
while model.episode <= 100:
model.step()可視化
エージェントが学習している過程を見ていきます。
ちなみに作成した動画をgifファイルで保存したければ、作成後に
from matplotlib.animation import PillowWriter
anim.save("・.gif", writer="pillow", fps=60) #・は名前としてください。60fpsのgifファイルが作成されます。
なお、今回はmesaの可視化モジュールは使用していません。
# 初期位置での迷路の様子
import matplotlib.pyplot as plt
# 図を描く大きさと、図の変数名を宣言
fig = plt.figure(figsize=(5, 5))
ax = plt.gca()
agent_counts = np.zeros((model.grid.width, model.grid.height))
# 赤い壁を描く
plt.plot([0.5, 1.5], [0.5, 0.5], color='red', linewidth=2)
plt.plot([1.5, 1.5], [0.5, 1.5], color='red', linewidth=2)
plt.plot([1.5, 2.5], [1.5, 1.5], color='red', linewidth=2)
plt.plot([0.5, 0.5], [1.5, 2.5], color='red', linewidth=2)
# 状態を示す文字S0~S8を描く
plt.text(0, 0, 'S0', size=14, ha='center')
plt.text(1, 0, 'S1', size=14, ha='center')
plt.text(2, 0, 'S2', size=14, ha='center')
plt.text(0, 1, 'S3', size=14, ha='center')
plt.text(1, 1, 'S4', size=14, ha='center')
plt.text(2, 1, 'S5', size=14, ha='center')
plt.text(0, 2, 'S6', size=14, ha='center')
plt.text(1, 2, 'S7', size=14, ha='center')
plt.text(2, 2, 'S8', size=14, ha='center')
plt.text(0, -0.2, 'START', ha='center')
plt.text(2, 1.8, 'GOAL', ha='center')
# 描画範囲の設定と目盛りを消す設定
ax.set_xlim(-0.5, 2.5)
ax.set_ylim(-0.5, 2.5)
plt.tick_params(axis='both', which='both', bottom='off', top='off',
labelbottom='off', right='off', left='off', labelleft='off')
line, = ax.plot([0], [0], marker="o", color='g', markersize=60)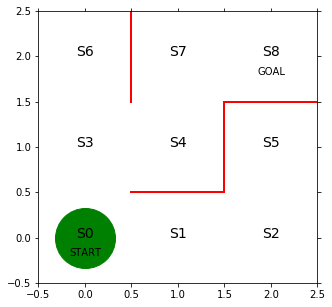
エージェントの行動記録をmodel.datacollectorからDataFrameとして受け取ります。
agents_data = model.datacollector.get_agent_vars_dataframe()図の緑の丸はエージェントの初期位置で、赤の線は通行禁止を表しています。
エージェント(=緑の丸)の移動の様子を描写していきます。
# 可視化, 今回はmesaのvisualizationは使わない
import matplotlib
from matplotlib import animation
from IPython.display import HTML
state = list(agents_data["state"])
def init():
'''背景画像の初期化'''
line.set_data([], [])
return (line,)
def animate(i):
'''フレームごとの描画内容'''
s = state[i] # 現在の場所を描く
x = s % 3
y = s // 3
line.set_data(x, y)
return (line,)
# 初期化関数とフレームごとの描画関数を用いて動画を作成する
anim = animation.FuncAnimation(fig, animate, init_func=init, frames=len(
state), interval=200, repeat=False)
HTML(anim.to_jshtml())
最初、エージェントはさまよっていますが、中盤以降は目的地に確かに向かっている様子が見えると思います。[5]
データ
エージェントがゴールするまでにかかったステップ数の推移をみていきます。
agents_dataは上で得たDataFrameです。
agents_data.xs(0, axis=0, level=1).head()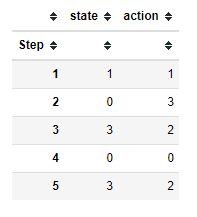
# 各agentごとのstep数取得
steps = []
for i in range(100):
info = agents_data.xs(i, axis=0, level=1)
steps.append(len(info))
len(steps)100# agentがゴールするまでのstep数の推移
plt.plot(range(100), steps)
plt.title("Q_learning")
plt.xlabel("episode")
plt.ylabel("steps")Text(0, 0.5, 'steps')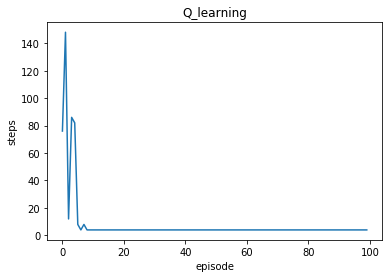
step数自体は10episodeほどから横ばいになっていることがわかります.
結論と雑考
MASの初歩として、まずは1体のエージェントでmesaを用いてQ学習を実装できました。
雑考として、複雑な環境において大規模なMARLを行うには工夫が必要なようです。素直に学習を進めると計算資源が豊富な場合を除いて行動価値関数Qの収束が遅い(または収束しない)場合があるためです。なので、はじめのうちはモデルの複雑さ、およびエージェントの数を制限してシミュレーションするほうが良いです。
脚注:
[1] 森:日本におけるマルチエージェントシミュレーション活用の動向; 情報処理,Vol. 55,No. 6,pp. 585-590 (2014)
[2] つまり今回はマルチエージェントシミュレーションというよりはエージェントベースモデルですね。
[3] ε-greedy法といいます。
[4] Q値の変化を記録したければ迷路モデルに渡してDataCollectorで集めてもいいかもしれません。
[5] エージェントにも、ジンクスがあるようで見ていて親近感がわきますね。