はじめに
これまで、データから因果構造を推定する方法として、統計的因果探索(Statistical Causal Discovery; SCD)が用いられてきました。SCDは観測データの変数間の相関だけではなく因果の方向を推定できる強力な手法であり、LiNGAMやPCアルゴリズムなどが広く用いられています。
しかし、実務でSCDを適用すると次のような問題に直面します。
・不自然な因果関係が出力される
データに依存しすぎると、常識的に考えてあり得ない因果パスが含まれてしまう。
・解釈に専門家の知識が必須
現場のドメイン知識を持つ人間が、結果を検証・修正しなければならない。
・知識を体系的に組み込むのが難しい
専門家の知見は貴重だが、網羅的かつ一貫性ある因果制約として表現するのは現実的に困難。
このように、SCDだけでは「データ駆動の因果発見」と「専門家の知識」の間にギャップがあり、それをどう埋めるかが大きな課題でした。
近年、この課題に対するアプローチとして、大規模言語モデル(LLM)の知識を統計的因果探索に組み込む研究が進んでいます。その代表例のひとつが、 SCP(Statistical Causal Prompting) で、2024年の論文 [^1] に詳しくまとめられています。
同時期に、ALCM(Autonomous LLM-Augmented Causal Discovery Framework) という枠組みも提案されています [^2]。両者は共にLLMを因果探索に組み込む点では共通しますが、SCPが統計モデルを基盤にLLMを補強的に用いるのに対し、ALCMはLLMを中心に自律的に因果グラフを修正するという違いがあります。
今回は、論文内に手順が詳細に示されているSCPフレームワークを実装してみました。
本記事ではまずはSCPを簡単に紹介し、その後、実際に実装して売上・ウェブサイトデータに適用した結果を紹介します。
SCP(Statistical Causal Prompting)とは何か
まずSCPとは何かについて解説します。SCP(Statistical Causal Prompting)は、統計的因果探索(SCD)の結果を大規模言語モデル(LLM)に渡し、その知識によって因果関係の妥当性を補強し、再度SCDに反映させるフレームワークです。
SCD単独ではデータ駆動的に因果グラフを生成しますが、しばしば不自然な因果関係が含まれます。SCPはこの問題に対して「LLMによるドメイン知識の補完」を導入し、より自然で解釈可能な因果構造を得ることを目指しています。
図1:Overall framework of the statistical causal prompt in a large language model (LLM) and statistical causal discovery (SCD) with LLM-based background knowledge. [^1]

SCPの流れ
SCPは以下の4ステップから構成されます。
1. SCDの実行
PC、Exact Search、DirectLiNGAMといったSCDアルゴリズムを適用し、因果構造を推定する。
ブートストラップを行い、各因果パスの出現確率を算出する。
2. 知識生成(Knowledge Generation)
LLMに対して「SCDで得られた因果関係」を提示する。
例:「変数A→変数B(bootstrap probability=0.35)」のような情報を与え、「この因果関係はドメイン知識的に自然か?」と問いかける。
LLMはその因果関係の妥当性について説明を生成する。
3. 知識統合(Knowledge Integration)
生成された説明を踏まえて、LLMに「この因果関係はYesかNoか」を回答させる。
その際、回答のログ確率(信頼度)も取得し、因果関係ごとに確率値を割り当てる。
4. Prior Knowledgeとして知識を再利用しSCDを強化
得られた確率値をPrior Knowledge Matrixに変換する。
一定の閾値(例:0.05以下なら禁止、0.95以上なら強制)でエッジを制約し、再度SCDを実行する。
SCPの特徴
SCPには以下のような特徴があります。
・双方向的な補完
SCDの結果をLLMに渡すことで、LLMは統計情報を踏まえた判断ができます。逆に、LLMの知識をSCDに戻すことで、因果構造が現実の直感に合致しやすいものになります。
・ドメイン知識をシステマティックに取り込める
人間の専門家が一つひとつの因果関係を検証する代わりに、LLMが自動的に知識を補完する仕組みを提供することで、人が担っていた部分も一貫したプログラムで行える。
これにより、人間による介入なしでより自然な因果探索を一貫して行うことができるので、ドメイン知識がなくても因果仮説の設計を高速で行うことができます。
実際に実装してみた
今回は、WEBサイトトラッキングデータと売上・LTVデータが合わさったダミーデータを用いて、WEBサイト上の活動が売上指標に与える因果効果を推定するという目的の前段階として、変数間の因果仮説を立てるためにSCPフレームワークを用いてみました。
なお、SCDのアルゴリズムにはDirectLiNGAMを採用しています。後に詳述しますが、アルゴリズムがDirectLiNGAMの場合は、2回目のSCDに入力する事前知識がDAG(有向非巡回グラフ)である必要があるので、Step 3 においてLLMから出力された事前知識を循環が無いように調整する必要があります。
Step 1. 純粋なSCD(統計的因果探索)
このステップは、まずは純粋にSCDを実行し、基準となる因果構造を得ることが目的です。
図2:SCDの結果
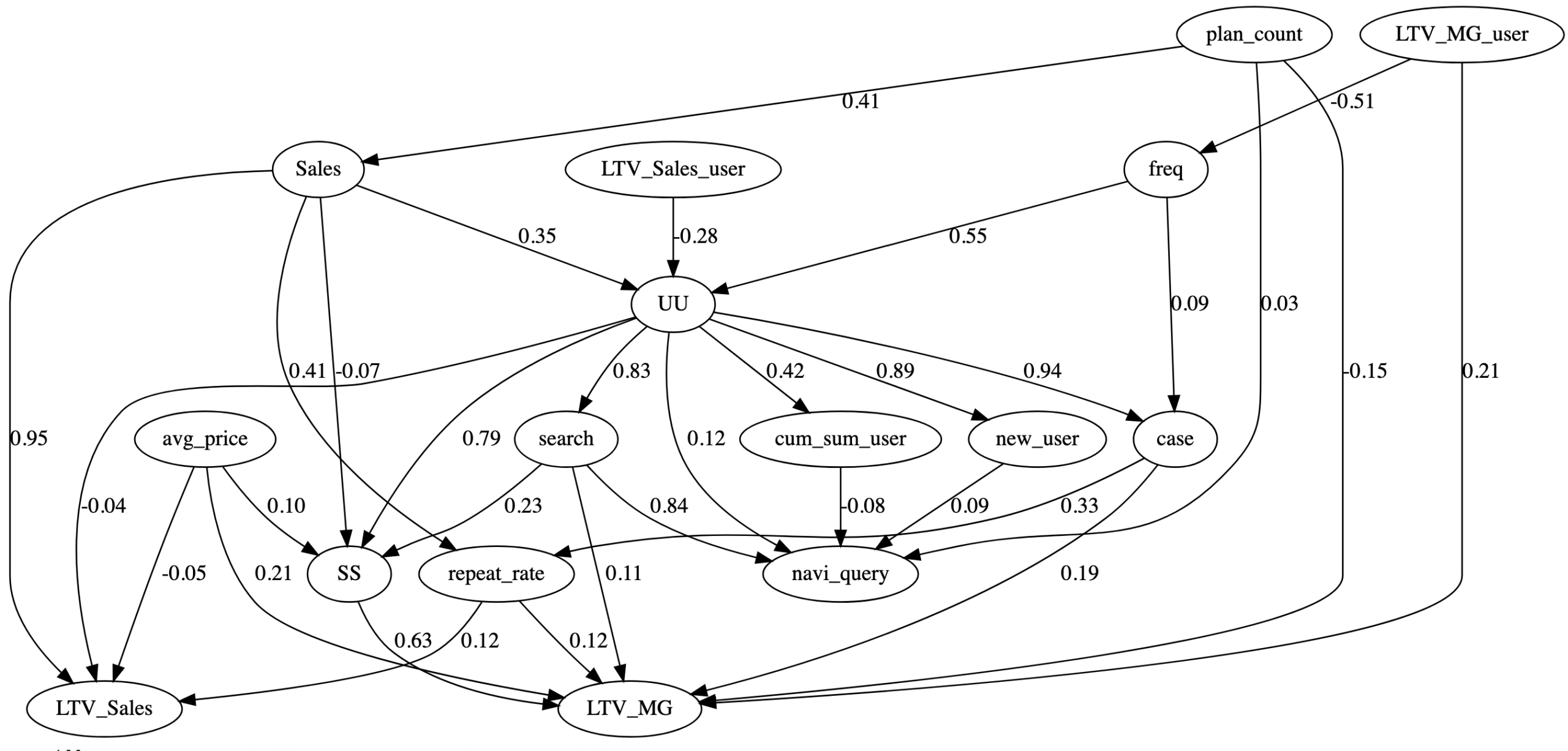
ダミーデータを標準化したのち、DirectLiNGAMを実行した際の隣接行列を有向グラフとして描画したものが上の図です。
この時点ではLLMは介入しておらず、あくまでデータから統計的に導き出した因果仮説です。
グラフからは、UU(サイトのユニークユーザー数)が主な起点となり、navi_query(ナビゲーションクエリ)やLTV_MG(利益ベース合計顧客生涯価値)、LTV_Sales(売上ベース合計顧客生涯価値)に因果が流れていく図になっています。
しかし、いくつかの点で不自然な図になっています。
まず、LTV(顧客生涯価値)の指標は、売上や利益、顧客数、購入頻度などから計算するため、基本的に因果の下流にあるべきですが、LTV_Sales_user(売上ベース顧客生涯価値)、LTV_MG_user(利益ベース顧客生涯価値)などは上流にあり、因果の流れが一貫していないように見受けられます。
また、Sales(売上)に寄与しているWEBデータが十分に存在しません。逆に売上がWEBサイト上の行動を促進し、結果としてLTVが向上する…のようなおかしな因果になってしまっています。
このような問題点を克服するために、次からのステップではLLMのドメイン知識による補完を行います。
Step 2. 知識生成
Step2では、統計的に出た因果関係がドメイン知識的に妥当かどうかを評価します。専門家の知識をLLMで疑似的に代替することで、データだけでは補えない常識的な解釈を加えられます。
まずデータの基本的な説明(変数の意味やデータが取得された背景など)を行い、次にStep1で生成された隣接行列のデータをLLMに渡します。
データに存在する変数のすべてのペアに対して、統計的に導かれた因果関係は適切であるかを質問し、LLMは専門家の代わりにドメイン知識に照らし合わせて因果探索が適切であるかについて意見を述べます。
質問には、Takayama et al. (2024)[^1]の論文で紹介されている文章を使用しました。
図3:Prompt template used for the generation of expert knowledge of the causal effect from xj on xi. [^1]

図4:Prompt template used for the quantitative evaluation of the probability of GPT-4’s assertion that there is a causal effect from xj on xi. [^1]

Step 3-1. 知識統合
Step3では、Step2で得た知識を定量化して次の因果探索に統合することを目指します。
ここでは、Step2で行ったLLMへの質問内容とLLMからの返答をさらにLLMに投入し、このディスカッションを第3者の視点で観察し、変数間に因果の線(エッジ)が現れるかをYesかNoかの2択で答えさせます。
Yes/Noの形式にすることで、SCDに組み込み可能なPrior Knowledge(事前知識)として定量化できます。
その方法は、LLMの返答する文字列が出力された確率を取得するということを複数回行い、最後にその平均確率を算出します。
その確率が非常に高い場合は変数間のエッジを強制し、また確率が非常に低い場合にはエッジを禁止します。
実装時には確率0.95以上で強制、確率0.05未満で禁止という閾値を設定しました。
これに基づいて出力された変数間の強制エッジを描画したものが以下の図です(禁止エッジは省略)。
図5:知識統合で得た強制エッジ
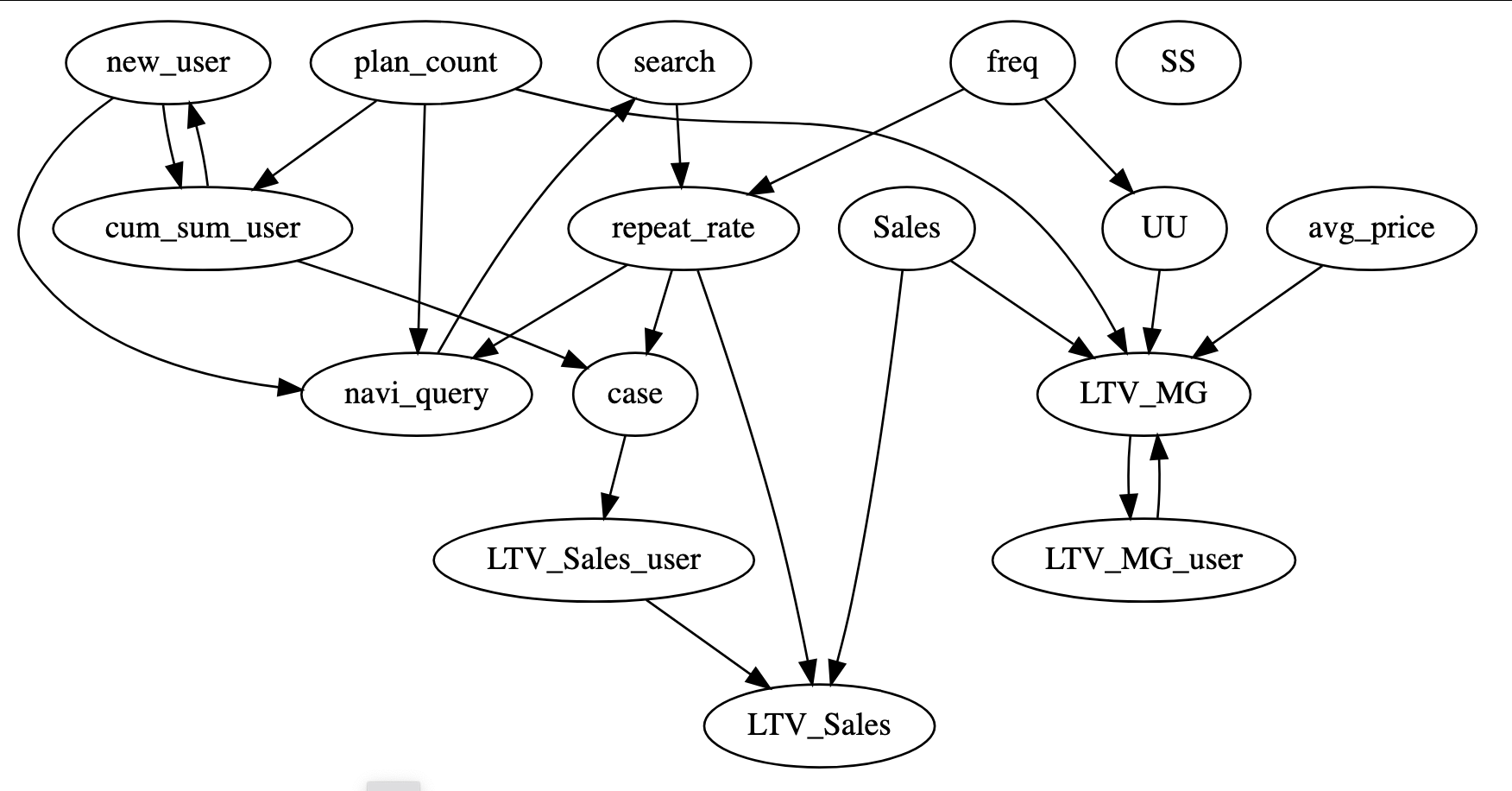
Step1の出力よりも大幅に簡略化された、エッジの少ないパス図になっています。
Step1で問題だったLTV系の指標はすべて下流に位置し、因果の流れがより自然になっています。LLMのドメイン知識による補完で、統計的な因果探索だけでは不自然に思われる部分が修正されていることがわかります。
ただしこの図には、いくつか変数間に循環が存在しています。
例えばnew_userとcum_sum_userにはどちらの変数からも他方にエッジが存在し、因果がループしてしまいます。同様に、LTV_MGとLTV_MG_userの間、navi_query → search→ repeat_rate → navi_queryの3変数間でも循環が発生しています。
今回使用したSCDアルゴリズムのDirectLiNGAMでは、循環が存在する事前知識を使用することができないため、次のステップでは循環が無くなるようにいくつかのエッジを削除します。
Step 3-2. Prior Knowledge (事前知識)のDAG化
エッジの削除方法は、循環をなすエッジの中で、最も重要ではないと思われる(そのエッジが作る循環の数が少ない)ものから順に削除していくというものです。
しかし、削除するエッジの候補が同時に複数存在する場合、それらのエッジを削除する順番の前後によって、結果的に作成されるパス図が変わってしまいます。
Step3-1の例で言えば、new_userとcum_sum_userどちらを先に削除するかによって結果が変わりうるということです。
そこで、すべての削除パターンを実行して、得られた因果図で構造方程式モデリング(SEM)を行い、最もデータへの適合性が高い(BIC基準で値が低い)ものを選択するという方法が論文では提唱されています。
このアルゴリズムにより選択された、循環のない事前知識が下の図になります。
図6:循環のない事前知識
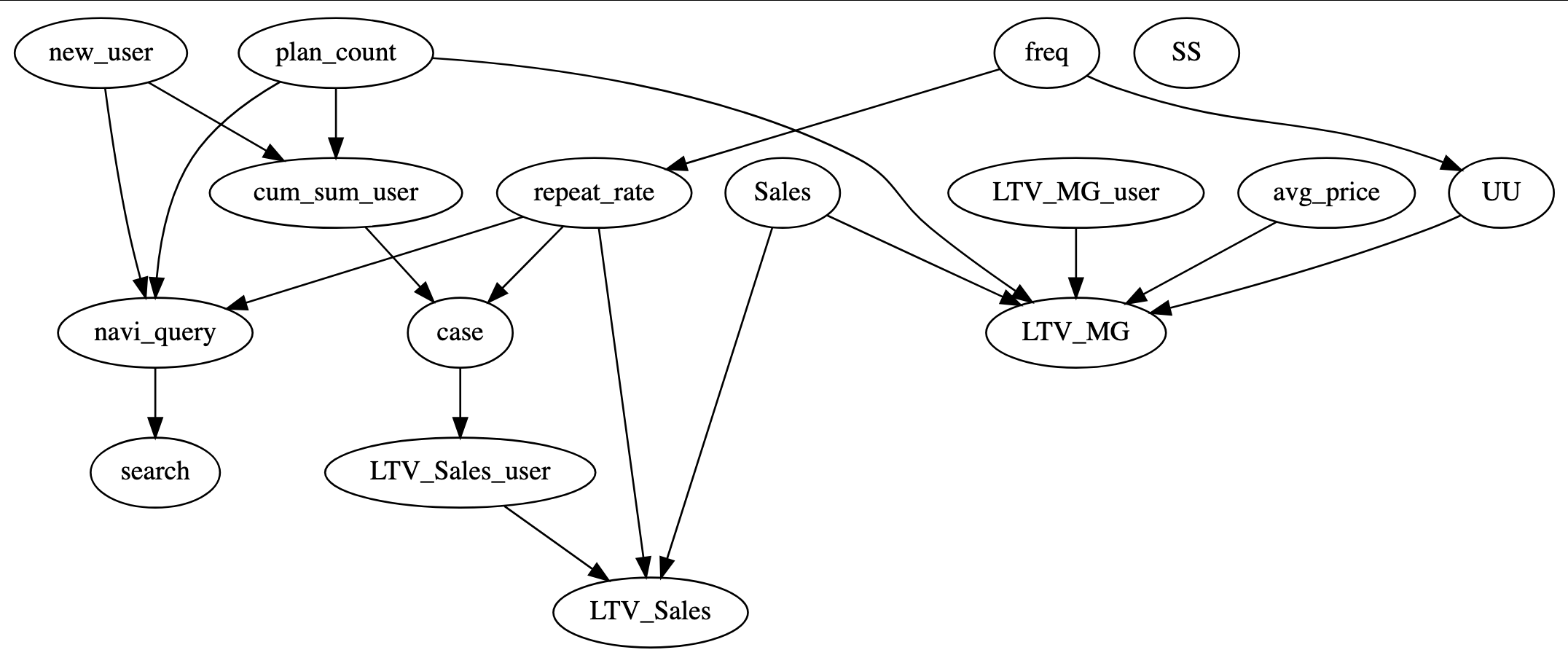
new_user(新規ユーザー数)、cum_sum_user(累積ユーザー数)間は、より直感的なnew_userからcum_sum_userへのエッジが選択されています。LTV_MG(利益ベース合計顧客生涯価値)、LTV_MG_user(利益ベース顧客生涯価値)間も自然な結果です。
ただし、navi_query → search→ repeat_rate → navi_queryの循環については、navi_queryとsearchがWEB検索系の変数、repeat_rateが購入リピート率であることを踏まえれば、削除するべきはrepeat_rate → navi_queryであるかもしれません。
ここではあくまで統計的に当てはまりのいい構造が選択されるようになっているので、部分的に不自然なエッジが残ることもあり得ます。しかし、もともとの循環の数が多いほど候補となる構造が指数関数的に増加するので、効率的に最良の候補を選択する方法としてBIC基準が使われています。
これにてLLMを用いた事前知識の生成と、SCDアルゴリズムへの統合準備が整いました。
Step 4. Prior Knowledgeによる制約を用いたSCD
最後に、Step 3-2 で生成された事前知識(Prior Knowledge)を用いて、もう一度 SCD を実行しました。このステップのポイントは、SCDの探索空間をLLMが補完した知識で制約することです。
実行してみた結果が以下の図です。
図7:事前知識を使ったSCD
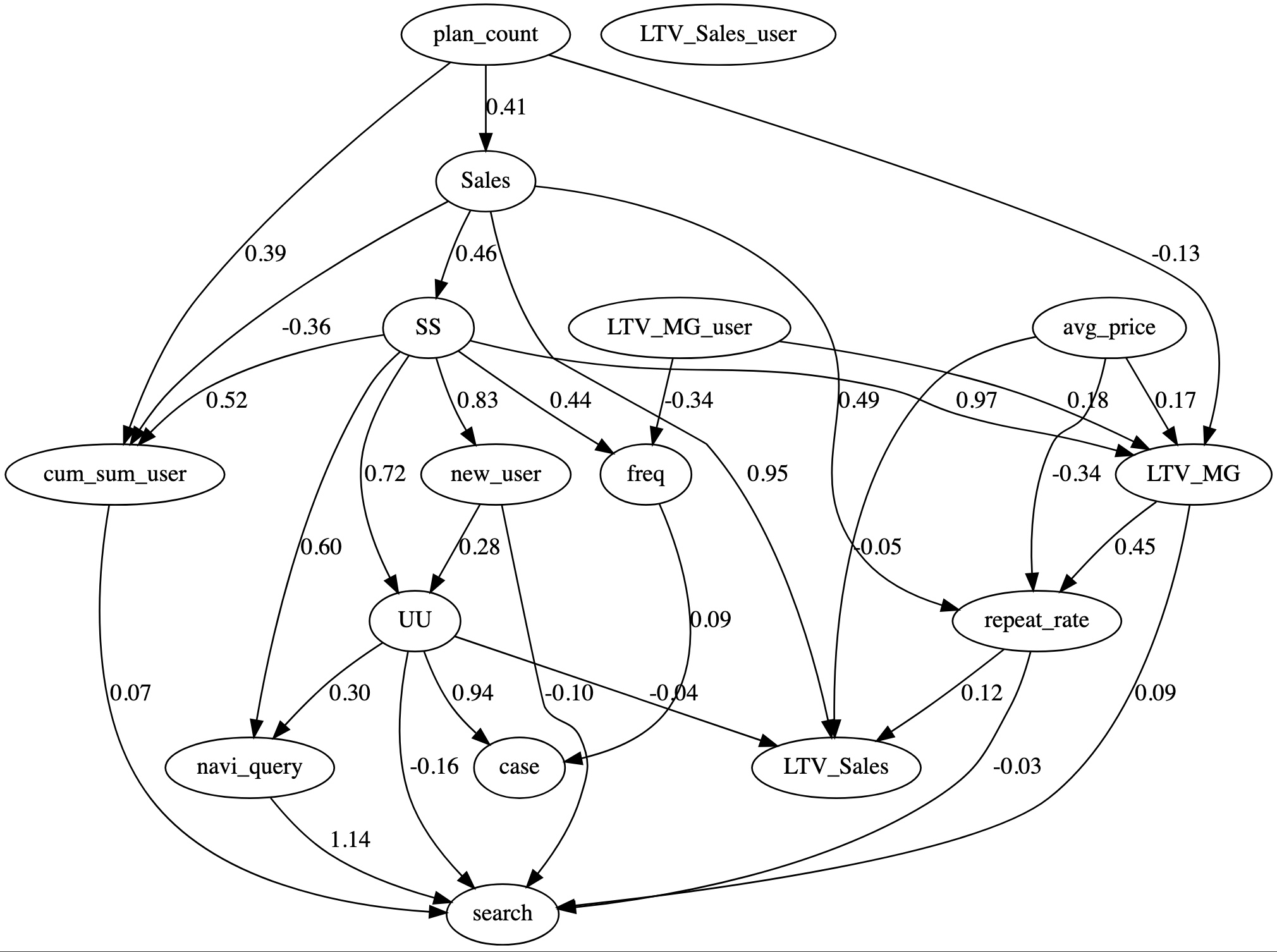
Step1よりも縦長の構造になり、変数間の因果の流れがよりまとまりのある見た目をしています。
Step1ではUU(ユニークユーザー)がハブとなりnavi_query、LTV_MG、LTV_Salesへという流れになっていましたが、Step4では、plan_countやSalesを経てSS(サイトセッション)がハブとなり、search、LTV_Salesに至る構造になりました。
Searchまでの流れを辿ると、プランの申込が増えると売上が上がり、それによってサイト上の活動が活発化し、新規ユーザー・ユニークユーザーが獲得され、検索が増える、というようなストックがフローを生み出す流れになっています。これは複数のユーザーによって発生するマクロな的な動きとして一理ありますが、ある一人のユーザーがWEBサイト上の活動からどのように購入に結びつくかというミクロの視点で因果を考慮していた場合はあまり有用な結果とは言えないかもしれません。
この結果となった理由として、時間差を考慮したVARモデルでなかったことや、LLMが変数の因果関係を正しく推測できていない、またはLLMが慎重でSCD後の不自然なエッジに対して強く反対することができなかった、などが考えられます。
おわりに
今回、SCPフレームワークを実際のデータに適用し、論文で紹介されている一連の手順を再現することができました。一貫して自動でドメイン知識がなくてもLLMによって因果探索を強化できるので、ドメインでの経験が浅くても因果推論を行いやすくなる可能性を秘めています。
一方で、今回のデータでは「直感的に不自然な因果関係が修正された」とはっきり言えるような改善は確認できませんでした。これはデータの性質やサンプル数、あるいはLLMの出力の安定性といった要因が関わっている可能性があります。
とはいえ、実装を通じてSCPの枠組みと制約を理解できたこと自体は大きな成果です。今後は、以下のような方向で発展させていきたいと考えています。
- 時間差を考慮したVARモデルへの拡張
今回は静的な因果探索に焦点を当てましたが、実際の広告効果や顧客行動には時間的な遅れが存在します。LiNGAMの時系列モデルとしてVAR-LiNGAMが知られていますが、現状では事前知識を適用する機能はサポートされていません。そのため、DirectLiNGAMを使って擬似的に時系列データに応用する方法を検討したいと考えています。 - LLMの「根拠」を追跡する
LLMが「この因果関係は妥当/不自然」と判断した背景をテキストとして可視化することで、解釈性を高めたいと考えています。ブラックボックス的にYes/Noだけを受け取るのではなく、Step2でのLLMの発言を分析する仕組みを作れば、因果仮説の理解も深まるはずです。 - 他のデータに応用してみる
広告やWEBサイト以外のドメインに適用することで、SCPの汎用性や限界を検証したいと思います。
関連ブログ
Statistical Causal Prompting (SCP) 実装レポート②:時系列因果探索への応用
参考文献
[^1]: Takayama, Masayuki; Okuda, Tadahisa; Pham, Thong; Ikenoue, Tatsuyoshi; Fukuma, Shingo; Shimizu, Shohei; Sannai, Akiyoshi (2024). Integrating Large Language Models in Causal Discovery: A Statistical Causal Approach. arXiv:2402.01454.
[^2]: Khatibi, Elahe; Abbasian, Mahyar; Yang, Zhongqi; Azimi, Iman; Rahmani, Amir M. (2024). ALCM: Autonomous LLM-Augmented Causal Discovery Framework. arXiv:2405.01744.

![[Rによる演習付き]操作変数法を理解する](https://blog.deepblue-ts.co.jp/wp-content/uploads/writing-828911_1920.jpg)
