
概要
この記事では, 「効果検証入門」のポイントをまとめ, 書籍内で行われている分析を掲載していきます.
(本記事は自分が勉強したことのまとめ的要素が強いので, 手元に書籍がある状態でお読みいただくことをオススメします)
尚, 分析コードについては著者が提供しているGitHubからダウンロードもできますので, 実際に手を動かしてみたい方は参考にしてください.
今回は第1章セレクションバイアスとRCTについて取扱います.
1.1 セレクションバイアスとは(P2~P6)
効果
-
ビジネス上のなんらかのアクション(広告展開, セールなど)を実施した際に売り上げなどのKPIに与えた影響を効果と呼び, そのアクションのことを介入と呼ぶ
- ただし特定の介入を測定するにはそれ以外の要員を取り除く必要がある
潜在的な購買量の差
- 介入(本書ではメールマーケ)をしなくても観測される売上を潜在的な購買量と呼ぶ
- 介入はコストの問題から限られた人数に実施されるが, シンプルに対象者と非対象者を比較するだけでは問題が発生する
誤った施策の検証
-
効率性の観点から, メール配信をする際にはある程度購買見込みのある顧客が対象となることが多いが, 以下の問題が発生する
- メール対象者はそもそもの購買量が大きいので, 非対象者と購買量に大きく差がつく
- 非対象者は潜在的な購買量が少ない
- このように得られた結果と本当の効果の乖離をセレクションバイアスと呼ぶ
1.2 RCT(Randomized Controlled Trial)(P6~P10)
本当の「効果」と理想的な検証方法
- 最も理想的な方法は同じサンプルに対して介入ありとなしそれぞれの結果を比較することだが, これは不可能→因果推論の根本問題と呼ばれている
RCTによる検証
-
介入を無作為に決めることが信頼のおける検証方法である→RCT(無作為化比較実験, Randomized Controlled Trial)
- これによって潜在的な購買量の差が等しくなり, 本来の効果が単純な比較で得られる
1.3 効果を測る理想的な方法(P10~P23)
母集団と推定
- 手元にある標本集団の結果から, 母集団の性質を推測することを推定という
ポテンシャルアウトカムフレーム
-
介入効果については以下のようにあらわせる.

-
また, 売上Yに関しては以下のように場合分けできる.
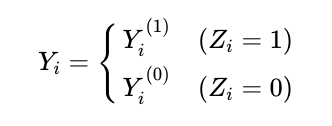
- この売上の差に介入の本当の効果があると考えることをポテンシャルアウトカムフレームと呼ぶ
- 売上Yはどちらかしか観測されないので, 観測されない側の結果をポテンシャルアウトカムという
ポテンシャルアウトカムフレームワークによる介入効果の推定
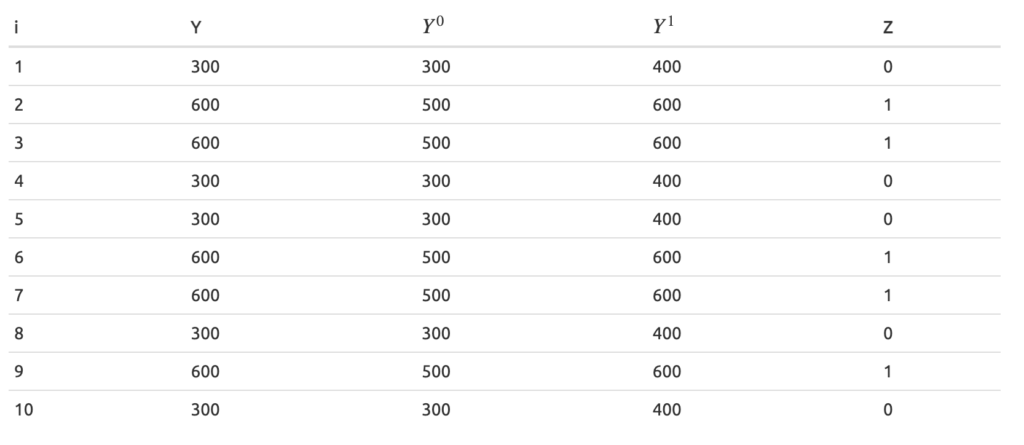
下記表ではそれぞれのユーザ売上(Y), ユーザにメールが配信された場合の売上とされなかった売上(Y^0, Y^1)とメールが配信されたか(Z)である
この表ではメールの効果が全てのユーザで等しく100となっている.
-
このデータにおいて介入の効果\tauは以下の式であらわせる. \tau = Y^{1} - Y^{0}
- ただし実際に観測できるのはYとZのみなので直接は計算できないのでグループ間の比較に注目する
平均的な効果
-
介入効果\tauは期待値の差であらわせる.
\tau = E[Y^{1}] - E[Y^{0}]- この効果を平均処置効果(Average Treatment Effect : ATE)とよばれている
平均的な効果の比較とセレクションバイアス
- 介入ありのユーザの平均売上は600, 介入なしのユーザの平均売上は300となるため, メールによって増加した売上は600 - 300 = 300となるが, すべてのサンプルでY^{1} - Y^{0} = 100となっているので, 効果を過剰に見積もっていることになる
-
このグループ間の比較は以下のような条件付き期待値を推定していることになる
\tau_{naive} = E[Y^{1}|Z=1] - E[Y^{0}|Z=0]- この\tau_{naive}が本当の介入効果とセレクションバイアスを足し合わせたものになる
- 今回のデータではE[Y^{0}|Z=1] = 500, E[Y^{0}|Z=0] = 300なのでセレクションバイアスの値は200となる
介入の決まり方がセレクションバイアスの有無を決める
-
セレクションバイアスとは, メール配信対象のユーザと, 配信対象にならないユーザにおける, メールを受け取らないときの売上の違い
- セレクションバイアスがによって効果が過剰(過少)に見積もられることがある
RCTを行った疑似データでの比較
-
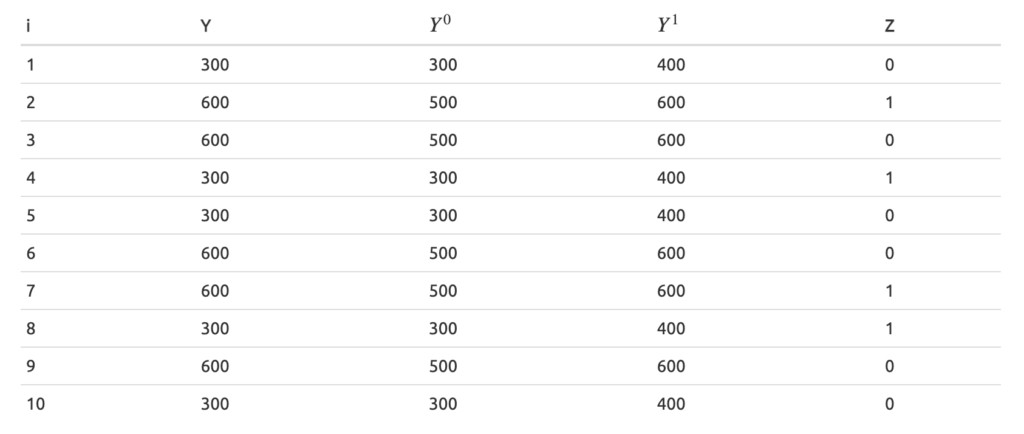
メール配信対象者はランダムに決定されるため, 潜在的な売上の期待値は0になる
E[Y0|Z=1] - E[Y0|Z=1] = 0- したがって,
\tau_{naive} = E[Y^{1}|Z=1] - E[Y^{0}|Z=0]
が施策の効果として信頼のおける推定値になる
- したがって,
ランダムに割り振ったデータ. 平均値の差は500-400=100となる. よってセレクションバイアスは0である
有意差検定の概要と限界
-
有意差検定(t検定)を行う
- 得られたp値が小さいほど, 平均の差が0である状態から得られたサンプルである可能性が低くなる(本著では5%未満で有意水準を設定している)
- よって(ここでは)p値が0.05以上であれば, 平均の差が0であることを否定できない
- ただし, 検定結果がセレクションバイアスの影響を受けることもあるので必ずしも効果を保証するとは限らない
1.4 Rによるメールマーケティングの効果の検証(P24~P33)
# ライブラリの読み込み
library(tidyverse)#データのダウンロード
email_data <- read_csv("http://www.minethatdata.com/Kevin_Hillstrom_MineThatData_E-MailAnalytics_DataMiningChallenge_2008.03.20.csv")#データの確認
head(email_data)
RCTデータの分析
male_df <- email_data %>%
#女性向けメール配信者を除外
filter(segment != "Womens E-Mail") %>%
#ダミー変数に変換
mutate(treatment = if_else(segment == "Mens E-Mail", 1, 0))summary_by_segment <- male_df %>%
#グルーピング
group_by(treatment) %>%
summarise(conversion_rate = mean(conversion),
spend_mean = mean(spend),
count = n())
summary_by_segment
#メール受信者の消費額を抽出
mens_email <- male_df %>%
filter(treatment == 1) %>%
#列の抽出に関してはselect()が一般的だがpull()でも可能
#pullの場合リストで抽出される
pull(spend)
#メール未受信者の消費額を抽出
no_mail <- male_df %>%
filter(treatment == 0) %>%
pull(spend)
#t検定
rct_ttest <- t.test(mens_email, no_mail, var.equal = TRUE)
rct_ttest
バイアスのあるデータの分析
set.seed(1)
#条件に反応するサンプル量を半分にする
obs_rate_c <- 0.5
obs_rate_t <- 0.5
#バイアスデータの作成
biased_data <- male_df %>%
#コントロール群
#購買傾向が低いサンプルに1を与える
mutate(obs_rate_c = if_else((history > 300) | (recency < 6) |
(channel == "Multichannel"), obs_rate_c, 1),
#トリートメント群
#購買傾向が高いサンプルに1を与える
obs_rate_t = if_else((history > 300) | (recency < 6) |
(channel == "Multichannel"), 1, obs_rate_t),
#乱数発生
random_number = runif(n = NROW(male_df))) %>%
#メール未配信かつ発生させた乱数が0.5未満のコントロール群を半分抽出
filter((treatment == 0 & random_number < obs_rate_c)|
#メール配信かつ発生させた乱数が0.5未満のトリートメント群を半分抽出
(treatment == 1 & random_number < obs_rate_t))summary_by_segment_biases <- biased_data %>%
group_by(treatment) %>%
summarise(conversion_rate = mean(conversion),
spend_mean = mean(spend),
count = n())
summary_by_segment_biases
#メール受信者の抽出
mens_mail_biased <- biased_data %>%
filter(treatment == 1) %>%
pull(spend)
#メール未受信者の抽出
no_mail_biased <- biased_data %>%
filter(treatment == 0) %>%
pull(spend)
#t検定
rct_ttest_biased <- t.test(mens_mail_biased, no_mail_biased, var.equal = T)
rct_ttest_biased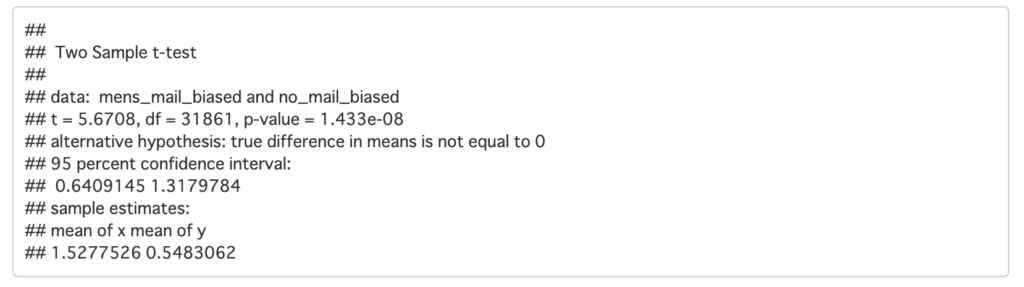
1.5 ビジネスにおける因果推論の必要性(P33~P38)
RCTの実行にはコストがかかる
-
実社会でRCTを実行するにはさまざまな障壁がある.
- ユーザをランダムに選択するため, 一時的に売り上げが減少してしまう可能性がある
- 何らかの施策や法律をランダムに割り振ることはコストだけでなく, 倫理的に問題がある
- ユーザによって提示する金額が違うと炎上のリスクがある
- このように理想的にはRCTで分析したいが不可能に近いという状態である.
セレクションバイアスが起きる理由
-
セレクションバイアスは人為的な介入によって発生する. 何故なら介入を選択する人が利得を高めようとした結果が現れているからである
- この行動を理解すれば, 誰のどのような意思決定がバイアスを生み出すかある程度想定ができる
ビジネスにおけるバイアスのループ
-
PDCAサイクルを回す際にバイアスのループに陥る可能性がある
- メール配信の例では1回目に各年代にメールを配信し, 次に効果が良さそうな世代にメールを配信して効果を高めようとするが, ここには年代によるセレクションバイアスが含まれる
- 例えば, 元々若者が多く購買しているものであれば, 若年層への効果が高いと見えてしまう
- これが繰り返されるとコストもかさみ, 過剰評価にも繋がるため, KPIの改善にならない
- 結果的にセレクションバイアスが大きくなり, 改善の知見は見せかけのものになってしまう
おわりに
次回は第2章介入効果を測るための回帰分析(前半)を掲載いたします.
最後までお読みいただきありがとうございました.

